





















L’industrie de la big data a rapidement évolué ces dernières années, avec une croissance de +62 % sur les 5 dernières années. Pourtant, seulement 12 % des entreprises utilisent réellement leurs données pour leurs cas d’usage métier (marketing, commerciaux, de support, etc.)
La Modern Data Stack (MDS) représente une évolution majeure dans la manière dont les entreprises gèrent et utilisent leurs données. La tendance est vers des architectures de données hautement personnalisables, où chaque entreprise peut construire sa propre solution "à la carte" en fonction de ses besoins spécifiques, tout en maintenant la flexibilité et l'adaptabilité.
👉🏼 Tour d’horizon de ce qu’est la MDS, de ses composants et de ses avantages dans cet article de blog.
Définition de la Modern Data Stack
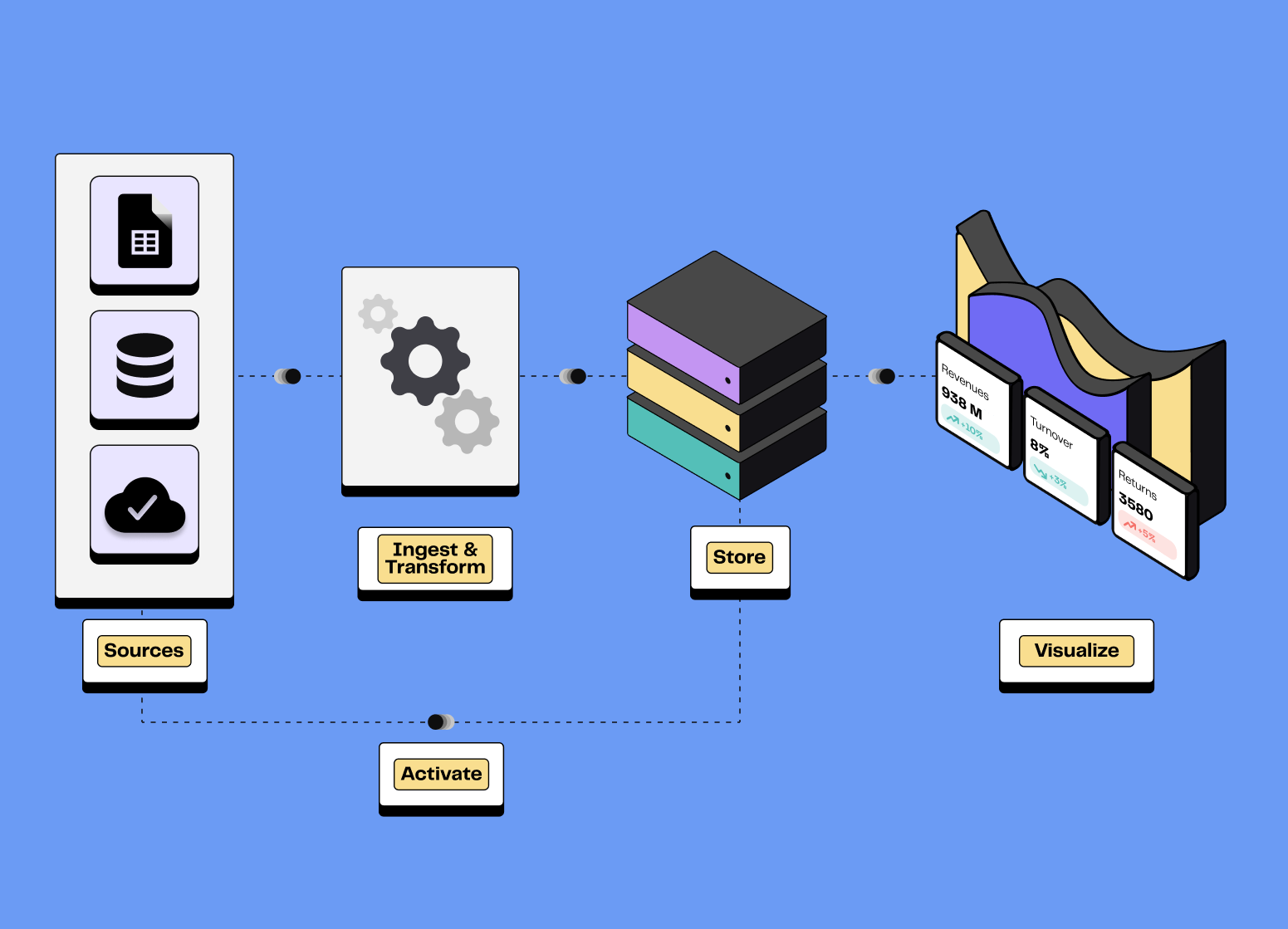
Aujourd’hui, la tendance est plutôt de stocker un maximum de données et de réfléchir par la suite aux cas d’usage qui peuvent être mis en place. Pour répondre à cet enjeu, la MDS se compose de briques spécifiques utilisées pour valoriser l’utilisation des données.
💡 La Modern Data Stack s’inscrit parfaitement dans le shift d’une vision centrée sur l’IT vers une vision centrée sur le business et permet à tous d’utiliser les données pour augmenter les performances générales de l’entreprise.
Chaque brique dans la MDS remplit une fonction spécifique, allant de l'ingestion des données à leur transformation jusqu'à la visualisation. Cette modularité offre plus de contrôle, une plus grande facilité de mise en place et une meilleure scalabilité. Chaque composant peut être adapté ou changé selon les besoins sans impacter l'ensemble du système.
La Modern Data Stack se caractérise par sa modularité, permettant aux entreprises de sélectionner les outils les plus adaptés à leurs besoins spécifiques. Les technologies utilisées dans la MDS mettent l'accent sur une excellente expérience utilisateur, ce qui facilite leur adoption à la fois par les équipes techniques et non techniques.
On parle de Modern Data Stack aujourd’hui car les solutions utilisées sont radicalement différentes de celles utilisées hier.
Avantages de la Modern Data Stack
Agile, modulaire et évolutive, la Modern Data Stack offre une gestion des données plus efficace et flexible par rapport aux architectures traditionnelles.
La MDS est souvent moins coûteuse que les data stacks traditionnelles, car les solutions basées sur le cloud adoptent un modèle de paiement à l'utilisation.
De plus, les data stacks ne sont plus limitées par les types de données. Elles peuvent désormais gérer facilement des données structurées, semi-structurées et non structurées (brutes). Cela facilite l'utilisation de diverses sources pour l’analyse et l’implémentation de différents cas d’usage.
La modularité de la Modern Data Stack offre une grande flexibilité. Chaque entreprise peut construire sa propre Data Stack en choisissant parmi une multitude de solutions disponibles. Chaque outil peut être remplacé facilement quand il ne convient plus. Les technologies composant la MDS sont généralement faciles à mettre en place et à utiliser, avec une interface utilisateur intuitive.
Enfin, un avantage souvent sous-estimé de la modern data stack est sa capacité à réduire certaines formes de dette technique. En remplaçant des systèmes fortement couplés par une architecture plus modulaire, les équipes gagnent en maintenabilité et en évolutivité.
Les 7 étapes d’un projet de Data Modern Stack
1️⃣ Audit
La première chose à faire est de réaliser un audit de la situation actuelle et de la maturité data de son entreprise pour lancer un chantier de Data Modern Stack.
L’audit passe par plusieurs phases :
Identification des outils et équipes existants : Cette étape est cruciale pour comprendre l'environnement actuel et les compétences disponibles dans les organisations. Par exemple, si l’entreprise dispose de plusieurs data engineers vs. de peu de ressources techniques, les choix d’outils ne seront pas nécessairement les mêmes.
Analyse des cas d'usage à mettre en place : Cette étape permet de déterminer comment la Modern Data Stack pourra soutenir les objectifs de l'entreprise : quelles sont les données à collecter (et quelles sont leurs sources), quelles sont les données à transformer (et comment le faire), comment activer ses données, etc.
Planification : Pour mener à bien un projet de Modern Data Stack, il est évidemment essentiel d’inclure les deadlines et les contraintes légales ou opérationnelles, telles que le RGPD, pour choisir des solutions compatibles.
⚠️ Il n’est cependant pas nécessaire choisir toutes les briques de sa MDS d’un coup. Il est pertinent d’analyser l’impact de chaque outil sur son organisation pour prendre les prochaines décisions avec un maximum d’informations.
2️⃣ Centralisation de la donnée
Data warehouses, data lakes, databases, on-premises, cloud hosted. La liste des solutions de stockage de la donnée s’agrandit au fur et à mesure des années.
Pour autant, stocker sa donnée et avoir une “source unique de vérité” doit être une priorité pour les entreprises. La centralité est essentielle pour permettre des analyses complètes et intégrées.
Avec l’augmentation des volumes de données disponibles, il devient nécessaire de choisir une solution performante, scalable (en termes de volume et de prix) et assurant la sécurité des données.
Chez DinMo, nous recommandons d’utiliser un data warehouse cloud comme source unique de vérité, pour des raisons de scalabilité et de performance. Des technologies comme BigQuery, Snowflake ou Redshift peuvent être envisagées.


Activation de la donnée d'un data warehouse vers les outils métier
💡DinMo est maintenant certifiée Google Cloud Ready, permettant une meilleure activation de sa donnée depuis BigQuery vers toutes les plateformes métiers.
3️⃣ Ingestion de la donnée
Une fois la solution de stockage déterminée, il est important d’y intégrer de manière automatique toutes ses données, provenant de multiples sources.
Les outils de type ETL (Extract, Transform and Load) ou ELT (Extract, Load, Transform) permettent de récupérer la donnée depuis les sources (emails, CRM, applications, etc.) et de la stocker dans le data warehouse cloud.
Ce type de processus permet de :
Combiner l’ensemble des données en une vue unifiée
Améliorer la productivité des données
Assurer un historique de données
Lors du choix d’outils d’ingestion de la donnée, il est essentiel de prendre en compte les coûts d'implémentation et d'opération pour des intégrations de données personnalisées vs. des solutions existantes d’ETL / ELT. Par exemple, des outils comme Fivetran ou Airbyte simplifient l'ingestion des données, réduisant le besoin en expertise technique.
4️⃣ Orchestration de la donnée
L’orchestration de la donnée est essentielle pour planifier et gérer les workflows, remplacer les interventions manuelles et suivre l’exécution des tâches. Les orchestrateurs permettent de planifier, organiser et surveiller des pipelines de données complexes.
Quelques outils connus sont Apache Airflow (outil open source) et Dagster (plateforme SaaS cloud native).
5️⃣ Transformation de la donnée
Une fois que les données brutes sont consolidées et hébergées, il faut les transformer pour assurer qu’elles soient prêtes à être utilisées pour des modélisations ou des analyses.
La transformation aide les entreprises à mieux organiser leurs données et à assurer leur qualité et leur facilité d’utilisation.
Les transformations peuvent être faites grâce à des processus internes, ou des outils SaaS ou Open source. Les outils les plus connus sont, par exemple, dbt ou Talend.
6️⃣ Activation de la donnée
Initialement, l’utilisation de la donnée se résumait principalement à des capacités de “visualisation” pour assister chaque équipe dans la lecture des résultats et la prise de décision. En réduisant les barrières techniques des outils de visualisation (pas besoin de code SQL), l'exploration des données et l’analytics sont devenus accessibles à tous.
Des outils tels que Looker Studio, PowerBI ou Qlik permettent aujourd’hui de créer des dashboards actionnables en quelques heures.
Cependant, l’activation de la donnée ne s’arrête pas ici. La visualiser pour prendre des décisions stratégiques est très bien, mais pouvoir l’utiliser directement dans des outils tiers est encore mieux.
Les Reverse ETL répondent donc à cette problématique, envoyant la donnée segmentée stockée dans le data warehouse, vers tous les outils opérationnels. Les cas d’usages permis par les Reverse ETL sont multiples aussi bien pour les équipes marketing, CRM, commerciales ou de support. Le tout sans avoir besoin de coder en SQL !


Activation de données
7️⃣ Observabilité
L’observabilité est souvent oubliée dans la Modern Data Stack, et pourtant elle est essentielle pour surveiller sa santé et sa performance. Pour cela, il est possible d’utiliser des outils de monitoring de la qualité des données (par exemple via des outils comme Sifflet), des catalogues de données (par exemple CastorDoc) et de suivi de l'utilisation des données pour maintenir l'efficacité de la stack :
Certains solutions offrent des protocoles de sécurité robustes, des techniques de chiffrement et des contrôles d'accès pour protéger les données
Le Data Catalog fournit aux utilisateurs la liste des données disponibles, du détail sur leur contenu, leur contexte et des métadonnées (telles que les descriptions, les schémas, les propriétés et les tags).
Quelques conseils pour construire sa Modern Data Stack
Avec beaucoup de “blocs” composant une Modern Data Stack, le projet peut vite devenir compliqué. Voici nos deux recommandations principales :
Mesurer le ROI : Concentrez-vous sur les cas d'usage spécifiques pour mesurer l'impact direct de la Modern Data Stack et procédez par itérations, en ajoutant ou en modifiant des composants en fonction des besoins et des résultats.
Approche itérative : Testez exhaustivement chaque nouvel élément avant de procéder à son déploiement à grande échelle, permettant ainsi une évolution fluide et contrôlée de votre stack.
Le site Modern Data Stack présente de nombreux exemples de stacks data mises en œuvre dans les entreprises, ce qui peut être une source d'inspiration si vous ne savez pas par où commencer. Le tableau présentant l'environnement du secteur data en 2025 fournit un point de départ simple mais efficace pour vous aider à démarrer rapidement !


Environnement Data 2025 - Crédit : https://mad.firstmark.com/
Conclusion
La Modern Data Stack représente une évolution majeure dans la manière dont les entreprises gèrent et utilisent leurs données, offrant une gestion des données plus efficace et flexible. Dans un écosystème évoluant rapidement, c'est un voyage constant d'adaptation et d'évolution, mais les avantages potentiels pour une entreprise sont énormes.
Le monde de la data de demain sera modulaire. Nous sommes convaincus que vous n’aurez plus besoin de passer par des acteurs de CDP traditionnelles, mais pourrez vous baser sur votre architecture existante pour construire votre propre CDP modulaire.
En fin de compte, l’objectif est de transformer les données en un atout concurrentiel pour l’entreprise, tout en simplifiant les opérations de données et en permettant une meilleure collaboration entre les équipes. Si vous avez des questions supplémentaires concernant la MDS et notamment l'activation de la donnée, n'hésitez pas à nous contacter !











