The central role of the Data Warehouse in a Modern Data Stack
8min • Last updated on Feb 5, 2026


Olivier Renard
Content & SEO Manager
The cloud data warehouse market was already worth $6.1 billion in 2023. By 2032, it is expected to exceed $37 billion, driven by an average annual growth rate of 22.5%, according to Global Market Insights.
This growth confirms the increasing interest of businesses in modern and scalable data architectures. The data warehouse is no longer a tool reserved for Business Intelligence (BI): it now plays a crucial role in centralising and leveraging data at scale.
Key Takeaways:
A data warehouse is a platform that centralises, organises, and makes a company’s or organisation’s data usable.
It differs from a database or a data lake in its structure, which is designed for analysis and decision-making. There are many providers on the market.
This warehouse acts as a central reference point by integrating data from various sources and maintaining its historical record.
It forms the foundation of a Modern Data Stack. A composable CDP leverages the data stored in the warehouse to enable activation by business teams — marketing, product, finance, sales.
🔍 Discover what a data warehouse is and how it stands apart from other storage solutions. Learn how to implement it and integrate it into your architecture to fully harness the power of your data. 🚀
What is a data warehouse
A data warehouse is a platform designed to integrate, store, and organise large volumes of data from various sources.
Its purpose is to support organisation-wide analysis and decision-making. In this way, it differs from a standard database, which is intended for routine operational tasks.
A data warehouse goes beyond simply collecting and storing information. It structures the data, preserves its history, and makes it usable for a wide range of needs: dashboards, KPIs, segmentation, modelling, and more. It serves as a reliable reference system, ready to feed business tools without requiring manual intervention.
Historically, the first data warehouses emerged in the 1980s, developed by pioneers such as Bill Inmon and Ralph Kimball. They were originally built to run on on-premise infrastructure, often complex to maintain.
Today, cloud data warehouses such as BigQuery, Snowflake, or Redshift offer far greater flexibility and ease of use. They integrate seamlessly with operational tools through connectors, APIs, or automated pipelines.
Main use cases
The role of the data warehouse has evolved significantly. Initially, it was mainly used for business intelligence and reporting, by aggregating data from across different departments of the company.
It enabled teams to track KPIs, generate consolidated reports, and ensure consistent interpretation of data.
Today, its usage goes far beyond BI. A modern data warehouse can be used to:
Create customer segments based on behaviour or historical data,
Feed scoring models or recommendation engines,
Enrich a 360° customer view,
Monitor product performance over time,
Gain deeper insight into the customer journey.
Marketing teams increasingly rely on this data to guide their strategies, personalise user experiences, and identify new growth opportunities. More broadly, the data warehouse serves the needs of all teams (product, finance, support), by providing structured, actionable insights.
What’s the difference between a data warehouse, a database, and a data lake?
To build an effective data architecture, it’s essential to understand the differences between a data warehouse, a relational database, and a data lake. Each has its own specific features, use cases, and limitations.
Criterion | Data warehouse | Database | Data lake |
|---|---|---|---|
Purpose | Centralises data for analysis, reporting, and decision-making (OLAP*) | Executes routine operations (transactions, records – OLTP*) | Stores large volumes of raw, varied data |
Data type | Historical, cleaned, analysis-ready data | Operational, real-time data | Raw, structured or unstructured data (files, logs, videos…) |
Cost | Moderate to high depending on use and volume | Lower cost at scale, but not built for analysis | Cheap to store, but more expensive to exploit |
Use cases | Dashboards, segmentation, multi-source analysis, data activation | CRM, order management, business apps | AI, machine learning, long-term storage |
Main providers | Snowflake, BigQuery, Redshift, Azure Synapse | MySQL, PostgreSQL, SQL Server | Amazon S3, Azure Data Lake, Google Cloud Storage |
Data warehouse vs Database vs Data lake
Two other concepts are frequently mentioned in data management: the data mart and the lakehouse.
A data mart is a smaller warehouse dedicated to a specific department or use case (marketing, finance, HR, etc.). It typically draws from a central data warehouse and offers fast access to targeted datasets.
The lakehouse, a term popularised by companies such as Databricks, refers to a hybrid architecture combining elements of both data lakes and data warehouses. Its goal is to bring together the best of both worlds: the flexibility of a data lake and the structure of a data warehouse.
How does it work in practice
A data warehouse is built on a simple yet powerful architecture, designed to make data both usable and trustworthy. Its operation relies on four key steps:
Ingestion: Data is collected from multiple sources (CRM, website, mobile app, ERP, etc.). It is integrated via ETL (Extract, Transform, Load) or ELT pipelines, depending on the context.
Storage: Data is stored in a stable environment with a clear structure, often using star or snowflake schemas.
Modelling: It is then organised around facts (e.g. 'purchases') and dimensions (e.g. 'customer', 'product', 'date') to enable easier querying and cross-referencing.
Delivery : Data can then be accessed, analysed, or activated in other applications.
Star and Snowflake schemas
Within a data warehouse, information is commonly structured according to two main models:
The star schema is simple, fast to query, and easy to maintain. All dimensions (e.g. 'customer', 'product', 'date') are directly linked to the fact table, like the branches of a star.
The snowflake schema is more detailed and more normalised, but also more complex. Dimensions are broken down into sub-tables to avoid redundancy. For example, the 'product' dimension might be divided into related tables such as 'size' or 'category.'
💡 The name Snowflake is a nod to this type of schema design, though the platform is by no means limited to it.

Star schema vs Snowflake schema
Governance and interoperability: The role of the data layer
The data layer is the central component of the data warehouse. It acts as a bridge between raw data sources (CRM, websites, shops) and business use cases.
Its role is to store, prepare, and standardise information to ensure data quality, consistency, and compatibility across other tools in the stack (BI, CRM, composable CDP, etc.).
The data layer also integrates governance and security rules, for example: restricting access to certain datasets based on team or role.
A modern data warehouse guarantees both governance (data quality, compliance, access rights) and interoperability with third-party tools. It ensures that every team can rely on trusted, documented data, available directly within their usual working environment.
How to design a data warehouse for your business
Building an effective data warehouse isn’t just about choosing a provider or technology.
It’s a strategic project that must be guided by concrete business needs.
Here are the key steps to help you implement a solution that fits your organisation:
1️⃣ Identify business requirements
First, you need to understand what your teams expect from data:
What decisions need to be supported?
Which metrics are critical?
Which data sources are currently underused?
It always starts with dialogue, particularly with the relevant teams: marketing, product, finance, support.
2️⃣ Select your data sources
Once the needs are clear, map out the data sources to be integrated.
These may include your CRM, website, points of sale, analytics tools, or logistics systems.
The goal is to centralise relevant data, whether structured or semi-structured, while maintaining quality.
3️⃣ Choose the technical architecture
Should your data warehouse be hosted on-premise, or should you go with a cloud-based solution such as Snowflake, BigQuery, Redshift, Databricks, or Synapse?
Cloud Data Warehouses (CDWs) offer more flexibility, better scalability, and stronger interoperability with the rest of the stack. They’re suited to most businesses and allow data teams to focus on higher-value tasks.
4️⃣ Design an appropriate data model
Data modelling defines how your data will be organised and linked. A clear model makes queries easier and helps structure your data around facts and dimensions.
It also powers dashboards, marketing scores, and financial reports without the need for manual reprocessing or duplication.
5️⃣ Integrate the data warehouse into your existing stack
Your data warehouse must work in harmony with the tools you already use: CRM systems, marketing platforms, financial software, BI tools, and more. This interoperability is what enables teams to fully exploit the data.
The DinMo composable CDP connects directly to your data warehouse to activate customer data without duplication.

How the DinMo composable CDP works
Mistakes to avoid
Designing without a clear objective: Without alignment on business needs, the project risks becoming a white elephant.
Overlooking data activation: Storing data isn’t enough. You need to plan from the outset how it will be used (e.g. segmentation, campaigns, automation).
Isolating the solution from end users: A data warehouse only creates value if it powers the tools that operational teams use daily.
The role of the data warehouse in a modern data architecture
The cloud data warehouse now holds a central position in the modern data stack. It serves as a foundational layer, supporting all other components in the company’s data ecosystem.
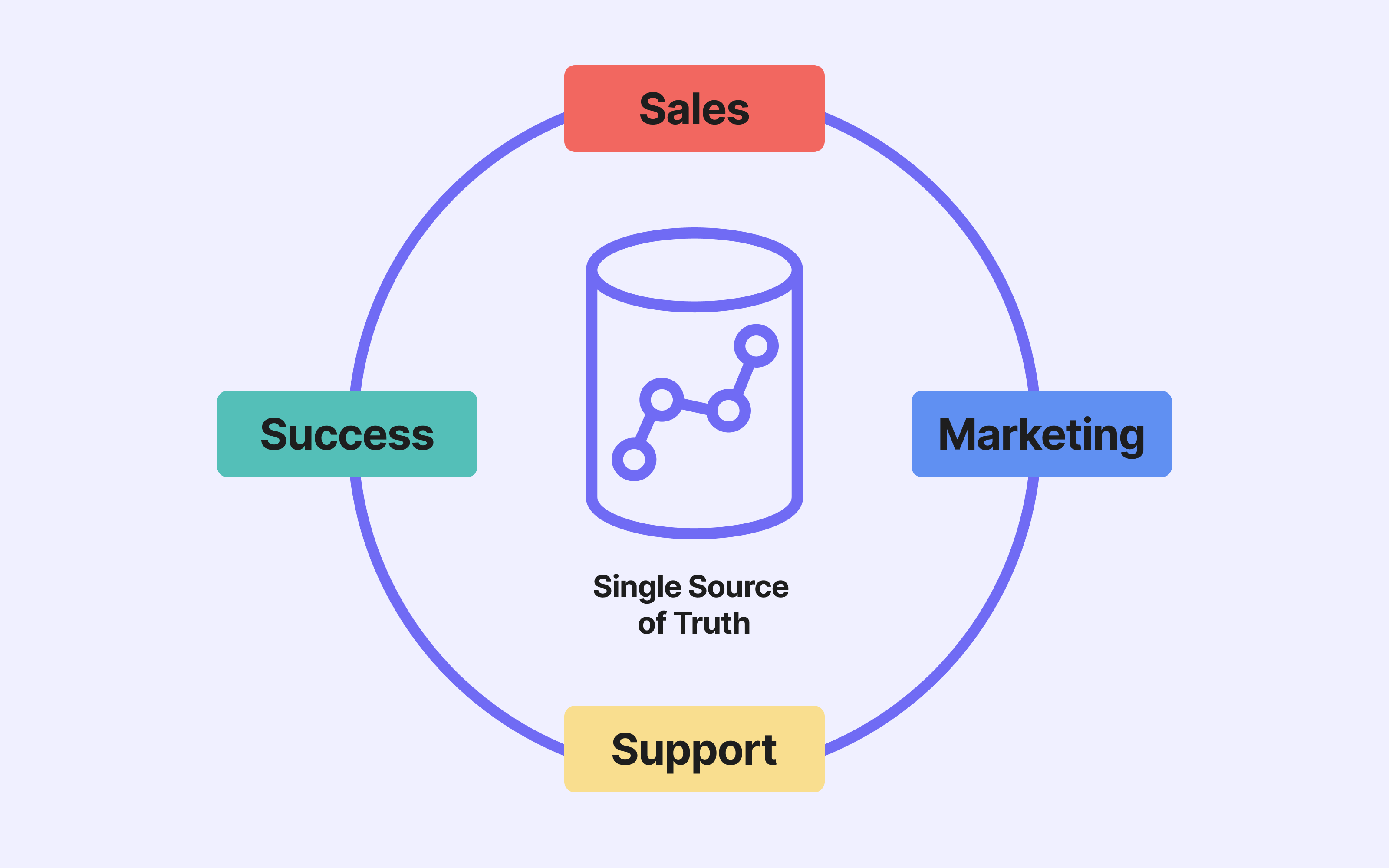
A single source of truth
By centralising data from multiple sources, the data warehouse enables the creation of a unified, up-to-date view.
It becomes the single source of truth, ensuring that every team works from the same figures, definitions, and business rules.
An interconnected component of the stack
The data warehouse is powered by ETL or ELT pipelines, which extract, transform, and load data. It can be connected to data observability tools that monitor data quality, freshness, and availability.
Finally, it can deliver data directly to business or analytics tools through connectors or platforms like DinMo, without duplication.
The strong complementarity between the data warehouse and the composable CDP
As we’ve seen, the data warehouse stores and structures data to make it usable by business teams. But for that to happen, data must be accessible within the tools they already use: CRM systems, advertising platforms, and more.
A composable Customer Data Platform (CDP) acts as a bridge to activate data stored in the data warehouse. Its modular architecture is what sets it apart from traditional (packaged) CDPs.
Packaged CDP vs Composable CDP
A packaged CDP bundles all functionalities (collection, storage, unification, activation) into a single tool. Because it stores data in its own database, it creates a second source of truth, separate from the company’s existing systems.
This often means higher initial costs, lower data security, and limited customisation.
In contrast, a composable CDP is built directly on the existing data warehouse. It doesn’t replicate data: it activates it at the source.
With this approach, DinMo empowers marketing, product, and sales teams to take action on their data without depending on technical teams.


Categories of CDP
Real-world use cases
This approach offers many practical benefits. It enables you to:
Segment customers based on behavioural or transactional data,
Enrich your CRM data with information from product usage or support channels,
Calculate and use Lifetime Value (LTV) in targeted marketing campaigns,
Deliver personalised customer experiences at scale.
The data warehouse remains the core foundation. The composable CDP builds on top of it to make data immediately useful and actionable, with no technical skills required.
Conclusion
The cloud data warehouse has become a strategic cornerstone of modern data architectures. It allows businesses to centralise, structure, and secure their data so they can analyse, activate, and generate value from it.
Long seen as a tool for technical teams, the data warehouse is now serving all business functions: marketing, product, sales, finance, leadership. Integrated into the wider stack, it provides access to high-quality, usable data that’s ready to drive performance.
👉 To go further with data activation, discover how the DinMo composable CDP helps you get the most from your data warehouse without duplication or technical bottlenecks.
*OLAP = Online Analytical Processing and OLTP = Online Transaction Processing
FAQ
What is a cloud data warehouse?
What is a cloud data warehouse?
A cloud data warehouse is a data storage solution hosted on cloud infrastructure, such as Snowflake, BigQuery, or Redshift.
Unlike traditional on-premise systems, it offers greater flexibility, automatic scalability, and seamless integration with modern data stack tools.
It enables businesses to store, structure, and analyse their data without managing servers — while also reducing infrastructure costs.
How is a data warehouse different from cloud storage?
How is a data warehouse different from cloud storage?
A data warehouse is designed to integrate, centralise, preserve, and organise data so that it becomes usable by teams and readily available for analysis.
Cloud storage, by contrast, is intended to hold files, whether structured or not, without any built-in analytical logic.
A data warehouse allows you to run queries, cross-reference datasets, and generate dashboards.
Cloud storage, on the other hand, is typically used as an archive or as a source for downstream processing.
What is the difference between a data lake and a data warehouse?
What is the difference between a data lake and a data warehouse?
A data lake stores raw data of all types — structured, semi-structured, or unstructured — in a flexible format, without strict organisation. This makes it particularly well-suited for exploratory analysis, large-scale processing, or machine learning (AI) use cases.
A data warehouse, by contrast, organises data to make it quickly and reliably analysable by business teams. Its purpose is to make information understandable and actionable.
Both can be complementary in a modern data architecture.