Modern Data Stack: what are the best tools?
10min • Last updated on Jan 6, 2026


Alexandra Augusti
Chief of Staff
The Modern Data Stack (MDS) consists of a set of technologies designed to enable the collection, storage, transformation, analysis, and visualization of data in an optimal and reliable manner. It relies on cloud-based, open-source, or integrated solutions. The main objective of the Modern Data Stack is to ensure great flexibility, scalability, and efficiency.
Are you considering developing or adding tools to your Modern Data Stack this year? You are in the right place!
💡 In this article, we will discuss what exactly a modern data stack is, why it is crucial for maximizing your data, and which tools to select to effectively meet your requirements.
Many solutions are part of this vast set, but the Modern Data Stack often remains challenging to explore due to the large number of players and functionalities.
👉🏼 We aim to highlight the main options available on the market to build your MDS, classified according to the different layers of the modern data stack.
What is the Modern Data Stack?
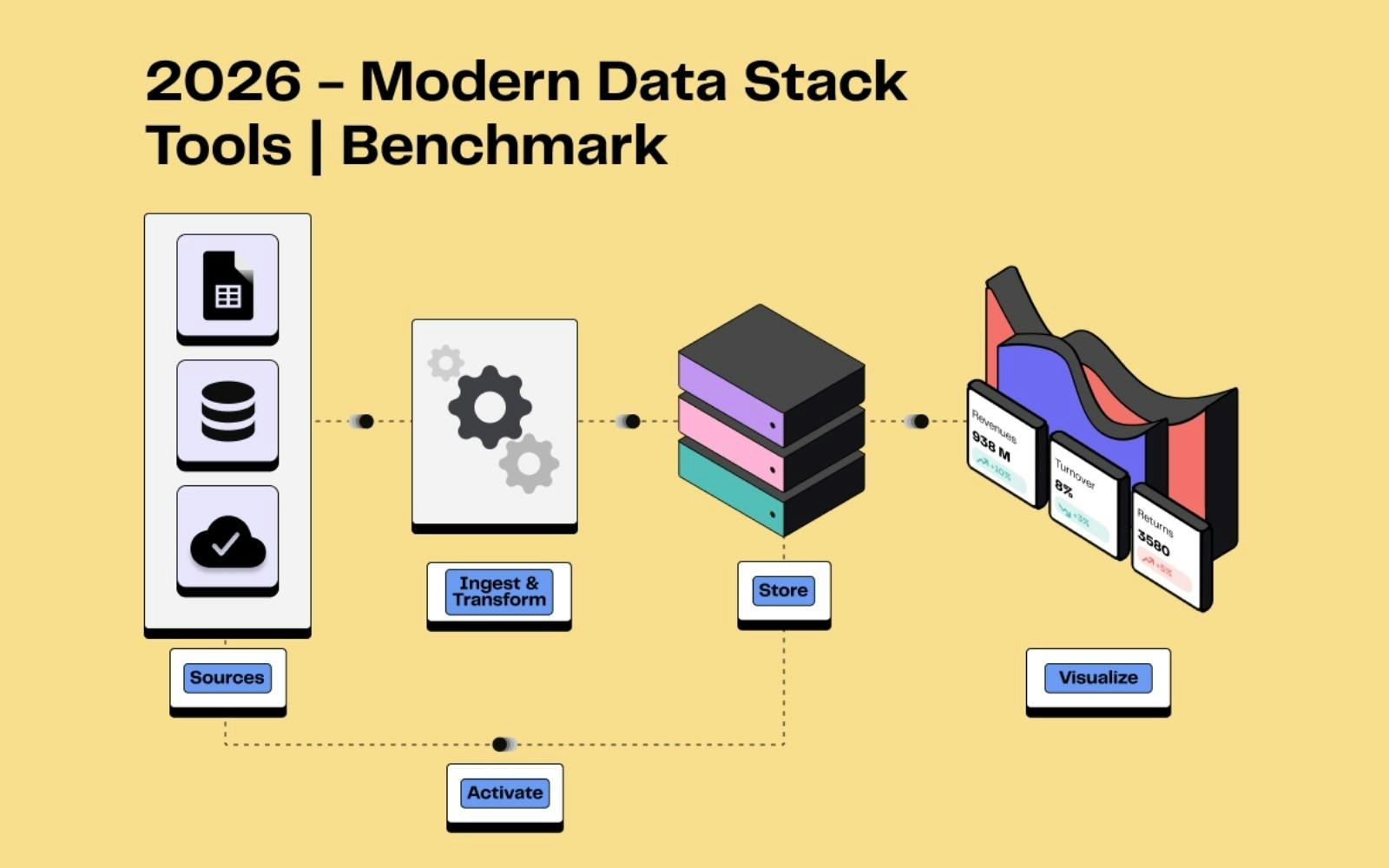
The Modern Data Stack (MDS) represents the technological arsenal intended for the collection, storage, processing, and analysis of data. Each component of the MDS fulfills a specific function and is often supported by a dedicated tool. This modularity ensures better controllability, ease of implementation, and scalability as each component can be adapted or changed according to needs without impacting the entire system.
The MDS breaks down into several essential components, described below:
Data Ingestion: The goal is to capture data from multiple sources to load it into an appropriate storage system. There are mainly two methods: ETL (Extract, Transform, Load) which transforms data before loading and ELT (Extract, Load, Transform) which proposes loading data first before transforming it.


Extract Transform Load process illustration
Data Storage: Several options exist, whether data warehouses, data lakes, or databases, each responding to specific needs in data structuring. Modern data storage solutions are largely cloud-based, ensuring scalability, performance, and cost reduction.
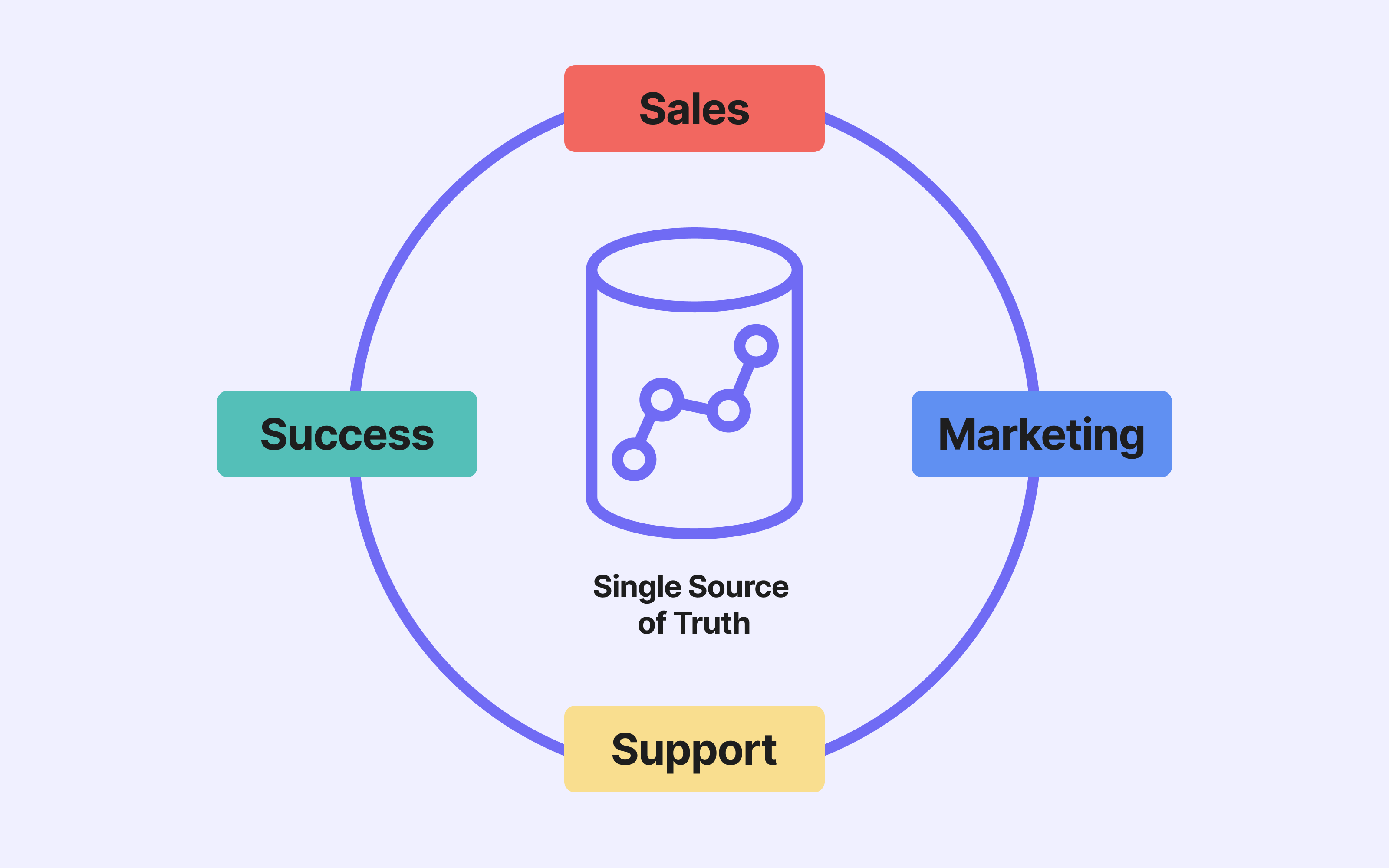
💡We recommend using your data warehouse as a single source of truth
Data Transformation and Orchestration: Data transformation aims to clean, enrich, and reorganize data to make it usable for analysis and visualization. Data orchestration automates and coordinates the steps of data transformation and their movement within the components of the MDS.
Business Intelligence: This encompasses the processes and tools allowing the exploration and visualization of data, generating reports and dashboards, and ultimately producing insights to aid decision-making.
Data activation (other than BI): Being able to use your data in third-party tools is now crucial to meeting customer expectations. The main method is Reverse ETL, which sends segmented data from a data warehouse to operational tools.
Reverse ETL can be used in a wide variety of ways, whether by marketing, CRM, sales or support teams.


Illustration of Reverse ETL process
Data Science: It includes methods and tools to apply advanced analysis processes, statistics, machine learning, and AI to data, aiming to create predictive models.
Data Catalog and Governance: The data catalog allows documenting, cataloging, and searching the data integrated into the MDS, offering a complete overview of sources, formats, schemas, and uses. Data governance refers to the standards and processes to ensure data security, compliance, and quality.
Observability: It concerns monitoring and diagnosing data systems, allowing the identification and resolution of incidents and anomalies.
Key Players in the Modern Data Stack
Several players position themselves on each functionality of the Modern Data Stack. However, it should be noted that some solutions seek to extend their offer and cover several functionalities.
👉🏼 In this article, we mention the main players of each layer of the MDS.
⚠️ Disclaimer: this list is not exhaustive, and the technological landscape contains other solutions that may better suit your specific needs. We only mention the most used solutions on the market and those we find with most of our clients.
We highly encourage you to consult other resources, especially on specific tools you might need.
Data Ingestion
Airbyte: With its promise to connect to more than 350 sources to your data warehouse, data lake, or database, Airbyte impresses with its intuitive user interface, horizontal scalability, reliability, and ease of maintenance. Compatible with leading data storage solutions like BigQuery, Snowflake, Redshift, etc., Airbyte is characterized by its open-source nature, meaning anyone in the community can develop a connector. Airbyte is the ideal choice for organizations looking to manage their data flows (integration and replication) with a modular and custom solution.
Fivetran: Fivetran, a SaaS software, ensures the connection of your data sources to your data warehouse in a few clicks. With support for over 500 sources and quick integration with enhanced security, Fivetran drastically simplifies data movement. Compatible with major storage players, this service is ready for companies seeking a turnkey solution.
Stitch: Stitch is an open-source tool, allowing a connection of 150+ data sources to your data warehouse in minutes. Integrations with the rest of the data stack are more limited compared to other data ingestion tools.
There are many other players in the ETL or ELT market. To choose the tool that best suits your needs, consider several factors: the number and type of connectors offered, the level of maintenance expected, the flexibility and scalability of the tool, and the support provided.
Data Storage
Storage solutions come in various forms, including data warehouses, data lakes, and hybrid solutions. The rapid adoption of the cloud has led to an explosion of cloud data warehouses:
BigQuery: Offered by Google, BigQuery is a cloud data warehouse designed to query structured and semi-structured data at scale. It is the most widely adopted data warehouse among mid-sized companies, particularly thanks to its cost-efficient pricing model.
BigQuery provides high-level performance, automatic scalability, pay-as-you-go billing, and tight integration with Google Cloud services. It is the platform of choice for businesses looking to work with large-scale, complex data using a robust and reliable solution.
Snowflake: Snowflake presents itself as a cloud data warehouse, efficient and flexible for managing structured and semi-structured data. In addition to storage, Snowflake also offers data ingestion, analysis, and visualization features.
AWS Redshift: An Amazon service, Redshift allows you to store and query your data quickly and securely. Known for its consistent performance, modularity, advanced security, and integration with AWS, Redshift is the ideal companion for companies wishing to analyze large amounts of data in the Amazon environment.
💡 Our recommendation is simple: if your stack already uses Google products, opt for Google BigQuery! Otherwise, turn to Snowflake.
Note that we are partners with both solutions and integrate seamlessly with their data environments.


DinMo is now a Snowflake Tech Partner!
If you want to opt for an open-source solution, you can turn to ClickHouse, a column-oriented OLAP database management system, known for being fast. Apache Pinot can also be a good open-source solution.
Transformation and Orchestration
This process also encompasses the automation and coordination of transformation tasks, as well as data routing through the different components of the modern data stack.
For data transformation, dbt is by far the market's reference solution. An open-source solution, dbt allows you to transform your data directly in your data warehouse using SQL. Its simplicity, modularity, reliability, and collaborative approach make dbt a preferred choice for those who wish to manage their data with agility in major data warehouses.
Dataform, Trifacta, and Rockset also allow data transformation.
For orchestration tools, we can notably mention:
Apache Airflow: This open-source tool, exploiting Python, allows the orchestration of your data flows via command lines. With Airflow, scheduling, monitoring, and orchestrating your data processes is simplified thanks to an approach based on operators, sensors, and clear UIs. Airflow is renowned for its great flexibility and is the market reference solution. Astronomer is a layer over Apache
Dagster: Dagster is a data orchestrator, providing a framework for building, testing, and deploying data pipelines. It is an open-source library for creating systems like ETL processes and Machine Learning pipelines.
Business Intelligence
BI tools are essential for allowing companies to analyze their performance and make data-driven decisions. This category is tough, as competition is fierce within this segment.
There are many players in the market, among the most well-known:


Gartner Magic Quadrant for BI
We wanted to develop those used by our customers:
Power BI: Developed by Microsoft, Power BI is known for its powerful features, flexibility, and connection with the Microsoft environment. The learning curve can be steeper for advanced features. Power BI offers integrated AI and ML functionalities. Power BI is the market leader, particularly in the large enterprise segment.
Looker: Looker Studio, part of the Google ecosystem, stands out for its ease of use and integration with all Google solutions (notably BigQuery, but also Google Analytics for marketing analyses). It offers a drag-and-drop visual builder. Due to its simplicity, Looker may be limited in the visualizations offered.
Tableau: Tableau is a data visualization tool owned by Salesforce, allowing raw data to be simplified and converted into a comprehensible format. It allows quick data analysis and the generation of visualizations in the form of tables and charts.
For visualization only, you can also turn to Metabase, which is very easy to use and allows you to create dashboards in a few minutes. Moreover, the pricing of Metabase is very interesting!
Data activation
We have written a dedicated article comparing the main Reverse ETLs vendors.
There are several categories of Reverse ETL:
Tools dedicated solely to data integration (Rivery, for example)
General-purpose Reverse ETL tools, which are more commonly used by data teams (e.g. Hightouch)
Reverse ETL tools for business teams, which free up time for data teams and empower marketing teams (like us, DinMo, for example).


Reverse ETL categories
Data Science
This discipline paves the way for innovation and solving complex challenges, with tools designed to simplify the development and deployment of data science solutions:
dataiku: Dataiku is a platform that simplifies data preparation work and the implementation of Data Science models. The solution is ideal for projects where customization and flexibility are key.
DataRobot: DataRobot is a solution for those who want to quickly implement machine learning and AI models without sacrificing quality or understanding of the results. DataRobot places particular attention on model governance and compliance.
It should be noted that Databricks is a complete platform overlaying your data warehouse with advanced Analytics and Data Science features.
Data Catalog and Governance
These crucial steps rely on dedicated tools to create and manage clear and accessible documentation:
Atlan: Atlan redefines data catalog management by promoting a collaborative approach. A solution designed for those looking to actively involve their team in data governance. It offers catalog, quality, lineage, exploration, etc.
Alation: Alation is a leading data catalog tool offering a user-friendly interface and robust features to help organizations leverage their data. With its AI-powered search capabilities and extensive metadata management, Alation enables users to easily discover and understand data assets.
Castordoc: Intuitive and simple, Castordoc offers data catalog management accessible to all. An economical tool for companies wishing to lead their cataloging project without complexity.
Data Quality & Observability
Data quality and observability mark the final layer of the modern data stack, aiming to ensure a solid decision-making base through reliable and high-performing data.
These tools allow precise management of data quality and observability indicators:
Monte Carlo: Monte Carlo offers a proactive view of your data and pipeline health, with increased observability. Monte Carlo uses artificial intelligence to monitor, identify, and correct data quality issues.
Great Expectations: Great Expectations is another popular data observability tool focused on data validation and integrity. It helps organizations define and implement data quality expectations, ensuring reliable and consistent data.
Conclusion
The Modern Data Stack represents a major evolution in how companies manage and use their data, offering more efficient, flexible, and cost-effective management. In a rapidly evolving ecosystem, there is a constant need for adaptation and evolution, but the potential benefits for a company are enormous.
If you have additional questions about the MDS and particularly data activation, feel free to contact us!
💡 If you want to see another company featured here, please send me an email. I'd be happy to get your feedback and content recommendations here: alexandra@dinmo.com