



















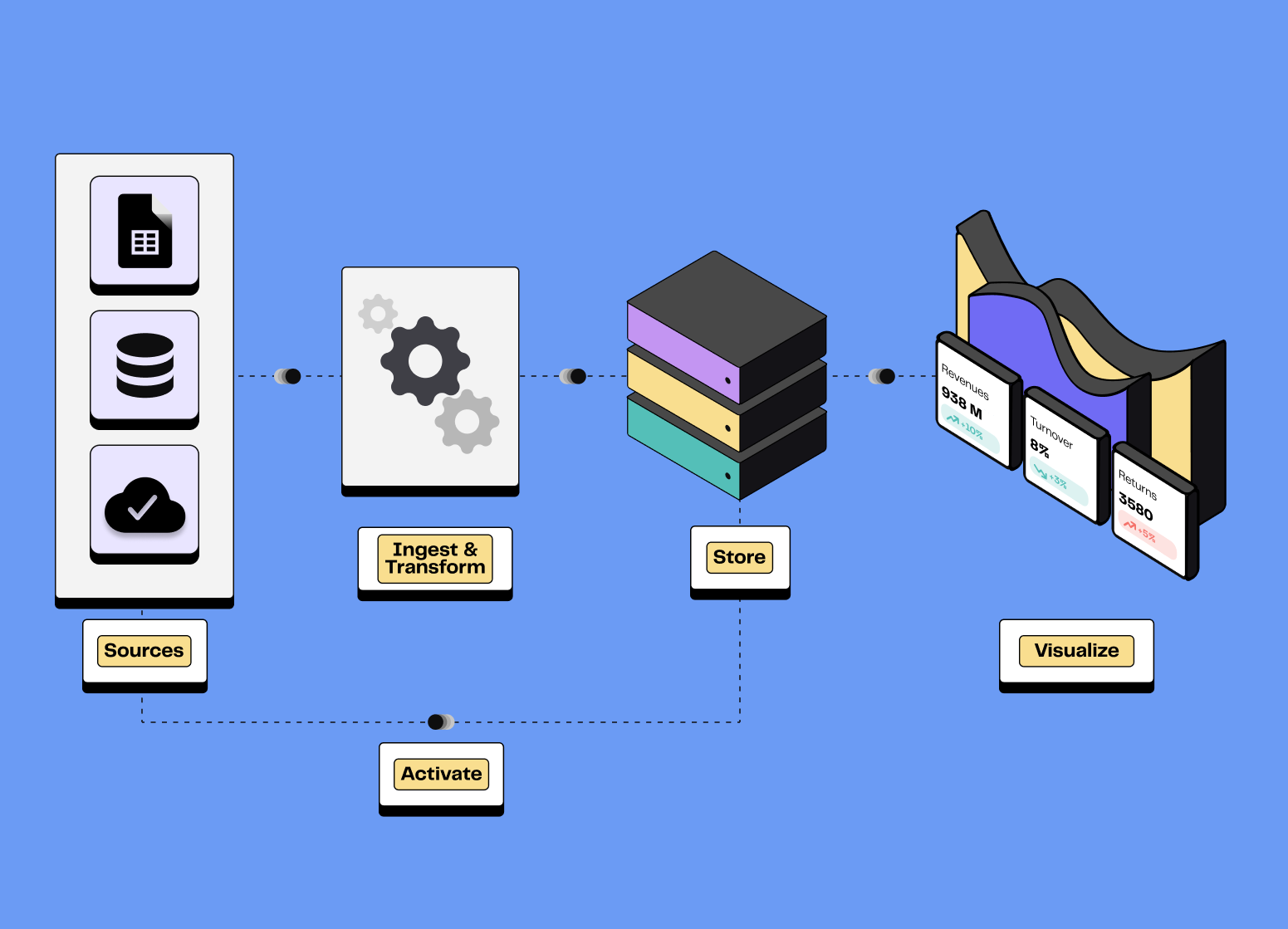
How to build your Modern Data Stack?
7min • Last updated on Jun 30, 2026


Alexandra Augusti
Chief of Staff
The big data industry has rapidly evolved in recent years, with a growth of +62% over the last five years. Yet, only 12% of companies actually use their data for their business use cases (marketing, sales, support, etc).
The Modern Data Stack (MDS) represents a major evolution in the way companies manage and utilise their data. The trend is towards highly customisable data architectures, where each company can build its own "à la carte" solution based on its specific needs, while maintaining flexibility and adaptability.
👉🏼 In this blog post, we provide an overview of what MDS is, its components, and its advantages.
Definition of the Modern Data Stack
Today, the trend is more towards storing as much data as possible and thinking about the use cases that can be implemented afterwards. To meet this challenge, the MDS consists of specific components used to enhance the use of data.
💡 The Modern Data Stack perfectly fits into the shift from an IT-centred vision to a business-centred vision in companies and allows everyone to use data to increase the overall performance of the company.
Each brick in the MDS fulfills a specific function, from data ingestion to transformation and visualisation. This modularity ensures better control, ease of implementation, and scalability, as each component can be adapted or changed according to needs without impacting the whole system.
The Modern Data Stack is characterised by its modularity, allowing companies to select the tools most suited to their specific needs. The technologies used in the MDS emphasise an excellent user experience, which facilitates their adoption by both technical and non-technical teams.
We refer to the Modern Data Stack today because the solutions it uses are radically different from those of the past.
Advantages of the Modern Data Stack
Agile, modular, and scalable, the Modern Data Stack offers more efficient and flexible data management compared to traditional architectures.
The MDS is often less expensive than traditional data stacks, as cloud-based solutions adopt a pay-as-you-go model.
Moreover, the data stacks are no longer limited by data types. They can now easily handle structured, semi-structured, and unstructured (raw) data. This facilitates the use of various sources for analysis and implementation of different use cases.
The modularity of the Modern Data Stack offers great flexibility. Each company can build its own Data Stack by choosing from a multitude of available solutions. Each tool can be easily replaced when it is no longer suitable. The technologies that make up the MDS are generally easy to set up and use, with an intuitive user interface.
Finally, one overlooked benefit of a modern data stack is its ability to reduce technical debt. By replacing tightly coupled systems and unclear data ownership with modular architecture, teams can reduce maintenance effort and improve long-term scalability.
The 7 Steps of a Modern Data Stack Project
1️⃣ Audit
The first thing to do is to perform an audit of the current situation and the data maturity of your company before starting a Modern Data Stack project.
The audit goes through several phases:
Identification of existing tools and teams: This step is crucial to understand the current environment and the skills available in the organisation. For example, if the company has several data engineers vs. few technical resources, the choice of tools will not necessarily be the same.
Analysis of use cases to be implemented: This step helps to determine how the Modern Data Stack can support the company's objectives: what data to collect (and their sources), what data to transform (and how to do it), how to activate its data, etc.
Planning: To successfully implement a Modern Data Stack project, it is obviously essential to include deadlines and legal or operational constraints, such as GDPR, to choose compatible solutions.
⚠️ However, it is not necessary to choose all the components of your MDS at once. It is relevant to analyse the impact of each tool on your organisation to make the next decisions with as much information as possible.
2️⃣ Data Centralisation
Data warehouses, data lakes, databases, on-premises, cloud hosted. The list of data storage solutions has expanded over the years.
However, it must be a priority for companies to store their data and have a 'single source of truth'. Centralisation is essential for enabling comprehensive and integrated analyses.
With the increase in available data volumes, it becomes necessary to choose a high-performance, scalable (in terms of volume and price), and secure data storage solution.
At DinMo, we recommend using a cloud data warehouse as the single source of truth for scalability and performance reasons. Technologies such as BigQuery, Snowflake, and Redshift are commonly used.


Activating data from a data warehouse to business tools
💡DinMo is now Google Cloud Ready certified, allowing better data activation from BigQuery to all business platforms.
3️⃣ Data Ingestion
Once the storage solution has been determined, it’s important to automatically integrate all data coming from multiple sources.
ETL (Extract, Transform and Load) or ELT (Extract, Load, Transform) tools enable the retrieval of data from sources (emails, CRM, applications, etc.) and store it in the cloud data warehouse..
This type of process allows for:
Combining all data into a unified view
Improving data productivity
Ensuring a data history
When choosing data ingestion tools, it’s essential to weigh the implementation and operational costs of custom data integration against existing ETL/ELT solutions. For example, tools like Fivetran or Airbyte simplify data ingestion, reducing the need for technical expertise.
4️⃣ Data Orchestration
Data orchestration is essential for planning and managing workflows, replacing manual interventions, and monitoring task execution. Orchestrators enable the planning, organising, and monitoring of complex data pipelines.
Some well-known tools are Apache Airflow (an open-source tool) and Dagster (a cloud-native SaaS platform).
5️⃣ Data Transformation
Once the raw data is consolidated and hosted, transforming it is essential to ensure it's ready to be used for modelling or analysis.
Transformation helps companies better organise their data and ensure its quality and ease of use.
Transformations can be done through internal processes, SaaS, or open-source tools. Well-known tools include dbt and Talend.
6️⃣ Data Activation
Initially, data use was primarily limited to 'visualisation' capabilities to assist each team in reading results and making decisions. By reducing the technical barriers of visualisation tools (no need for SQL code), data exploration and analytics have become accessible to everyone.
Tools such as Looker Studio, Power BI, or Qlik now allow the creation of actionable dashboards in only a few hours.
However, data activation does not stop there. Visualising it to make strategic decisions is great, but being able to use it directly in third-party tools is even better.
Reverse ETL addresses this issue by sending segmented data stored in the data warehouse, to all operational tools. The use cases enabled by Reverse ETL are multiple for marketing, CRM, sales, or support teams. All without needing to write a single line of SQL!
7️⃣ Observability
Observability is often overlooked in the Modern Data Stack, yet it is essential for monitoring its health and performance. For this, it is possible to use data quality monitoring tools (such as Sifflet), data catalogues (for example, CastorDoc), and data usage tracking to maintain the efficiency of the stack:
Some solutions offer robust security protocols, encryption techniques, and access controls to protect data
The Data catalogue provides users with the list of available data, details on its content, context, and metadata (such as descriptions, schemas, properties, and tags).
Some Tips for Building Your Modern Data Stack
With many "blocks" composing a Modern Data Stack, the project can quickly become complicated. Here are our two main recommendations:
Measure ROI: Focus on specific use cases to measure the direct impact of the Modern Data Stack and proceed iteratively, adding or modifying components based on needs and results.
Iterative Approach: Thoroughly test each new element before proceeding to its large-scale deployment, thus allowing for a smooth and controlled evolution of your stack.
The Modern Data Stack website presents many examples of data stacks implemented in companies, which can be a source of inspiration if you don't know where to start. The data landscape map provides a simple but effective starting point to help you get started quickly!


Data landscape 2025. Credit: https://mad.firstmark.com/
Conclusion
The Modern Data Stack represents a major evolution in the way companies manage and utilise their data, offering more efficient and flexible data management. In a rapidly evolving ecosystem, it's a constant journey of adaptation and evolution, but the potential benefits for a company are huge.
The data world of tomorrow will be modular. We are convinced that you will no longer need to go through traditional CDP providers but can rely on your existing architecture to build your own modular CDP.
Ultimately, the goal is to turn data into a competitive asset for the company, while simplifying data operations and enabling better collaboration between teams. If you have any further questions regarding MDS and especially data activation, do not hesitate to contact us!











