Comprendre le processus ETL : le guide complet
8min • Édité le 3 août 2025


Olivier Renard
Content & SEO Manager
Une entreprise utilise en moyenne 112 applications SaaS (BetterCloud). Un chiffre qui dépasse même les 150 pour les structures de plus de 5 000 salariés. C’est 40 % de plus qu’en 2020.
Face à cette prolifération d’outils, les données sont dispersées entre de multiples sources : CRM, ERP, plateformes e-commerce, analytics, support client… Centraliser, nettoyer et exploiter ces données est devenu un vrai défi pour les entreprises.
C’est précisément le rôle du processus ETL : transformer ce flux de données brutes en levier pour l’analyse et la performance.
Les informations à retenir :
L’ETL est l’acronyme d’Extract, Transform, Load. C’est un processus qui permet d’extraire, transformer et charger des données pour les rendre exploitables.
Il est essentiel pour consolider des données dispersées afin d’améliorer l’analyse, la business intelligence ou la relation client.
Le processus ETL se distingue d’autres modèles d’intégration, comme l’ELT. Le Reverse ETL désigne, lui, le mouvement inverse : l’envoi de données depuis un entrepôt vers les outils métier.
Bien choisir son outil ETL permet de simplifier la gestion des données et d’optimiser ses opérations data et marketing.
👉 Découvrez comment fonctionne le processus ETL, et pourquoi il reste un incontournable de toute stratégie data moderne. Retrouvez les outils à connaître et les cas d’usage principaux 🔍
Qu’est-ce que le processus ETL ?
L’ETL est le terme employé pour désigner la technologie Extract, Transform, Load (en français : extraire, transformer, charger).
Ce processus vise à collecter des données issues de multiples sources, les transformer, puis les importer dans un système cible pour qu’elles puissent être utilisées efficacement.
Il joue un rôle important dans la gestion et l’analyse des données. Sans ETL, les données restent souvent brutes, éparpillées et difficiles à exploiter.
En rassemblant et organisant l’information, l’ETL facilite l’analyse, la création de rapports, l’alimentation d’outils de business intelligence ou encore la construction d’une vue client unifiée.
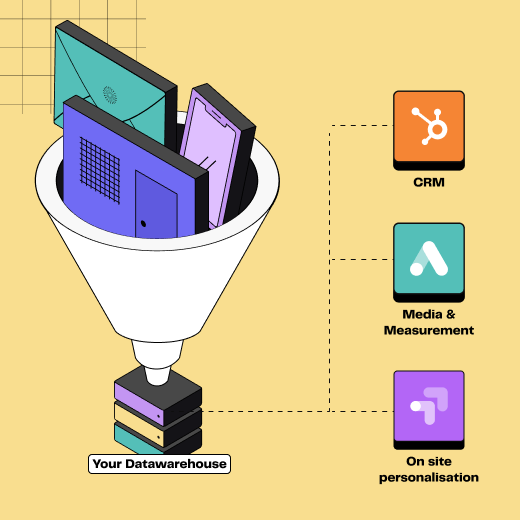
Un process en trois étapes
1️⃣ Extraction
La première phase consiste à récupérer les données depuis différentes sources.
Il peut s'agir de bases de données relationnelles (MySQL, Oracle), d’applications CRM, de plateformes e-commerce, d’API ou encore de simples fichiers CSV.
2️⃣ Transformation
Les données extraites sont souvent hétérogènes : formats différents, doublons ou informations manquantes.
La transformation consiste à les nettoyer, les enrichir, les reformater et parfois à les agréger pour les rendre cohérentes et prêtes à l’usage métier.
3️⃣ Chargement
Dernière étape : envoyer ces données transformées vers un data warehouse (entrepôt de données en français), un data lake ou tout autre système cible. Elles sont alors exploitables, que ce soit pour l’analyse, la personnalisation marketing ou le reporting.
Le chargement initial est complet, puis on effectue des chargements périodiques (ou incrémentaux).
💡 Dans certaines architectures modernes, les étapes d'extraction, de transformation et de chargement ne sont pas séquentielles. Elles peuvent s'exécuter en parallèle pour gagner du temps.


Illustration du processus Extract Transform Load
Importance dans la gestion des données
Explosion des sources de données
A l’origine, la donnée était stockée localement sur les serveurs internes de l’entreprise : factures, informations commerciales, stocks, RH. Les premières architectures data reposaient sur quelques bases relationnelles internes.
Aujourd'hui, les données viennent de partout : bases SQL et NoSQL, applications SaaS, objets connectés (IoT), logs d’activité, CRM, réseaux sociaux…
Cette multiplication des sources a engendré de nouvelles problématiques : formats de données différents, protocoles de connexion variés, qualité inégale, risques de doublons ou d’incohérences.
Sans une méthodologie claire pour organiser ce volume croissant d'informations, l’exploitation des données s’avère complexe, coûteuse et moins fiable.
Organiser la donnée pour l’analyse
Pour que les données puissent apporter de la valeur, elles doivent d'abord être centralisées, nettoyées et préparées. C’est l’objectif premier de l’ETL : consolider des informations hétérogènes afin de les rendre exploitables.
Ce processus est essentiel pour alimenter des outils de Business Intelligence, réaliser des analyses fiables ou déployer des projets de data science. Il constitue le socle d’une stratégie data-driven, en facilitant l’accès à des données précises et actualisées.
Un levier de performance
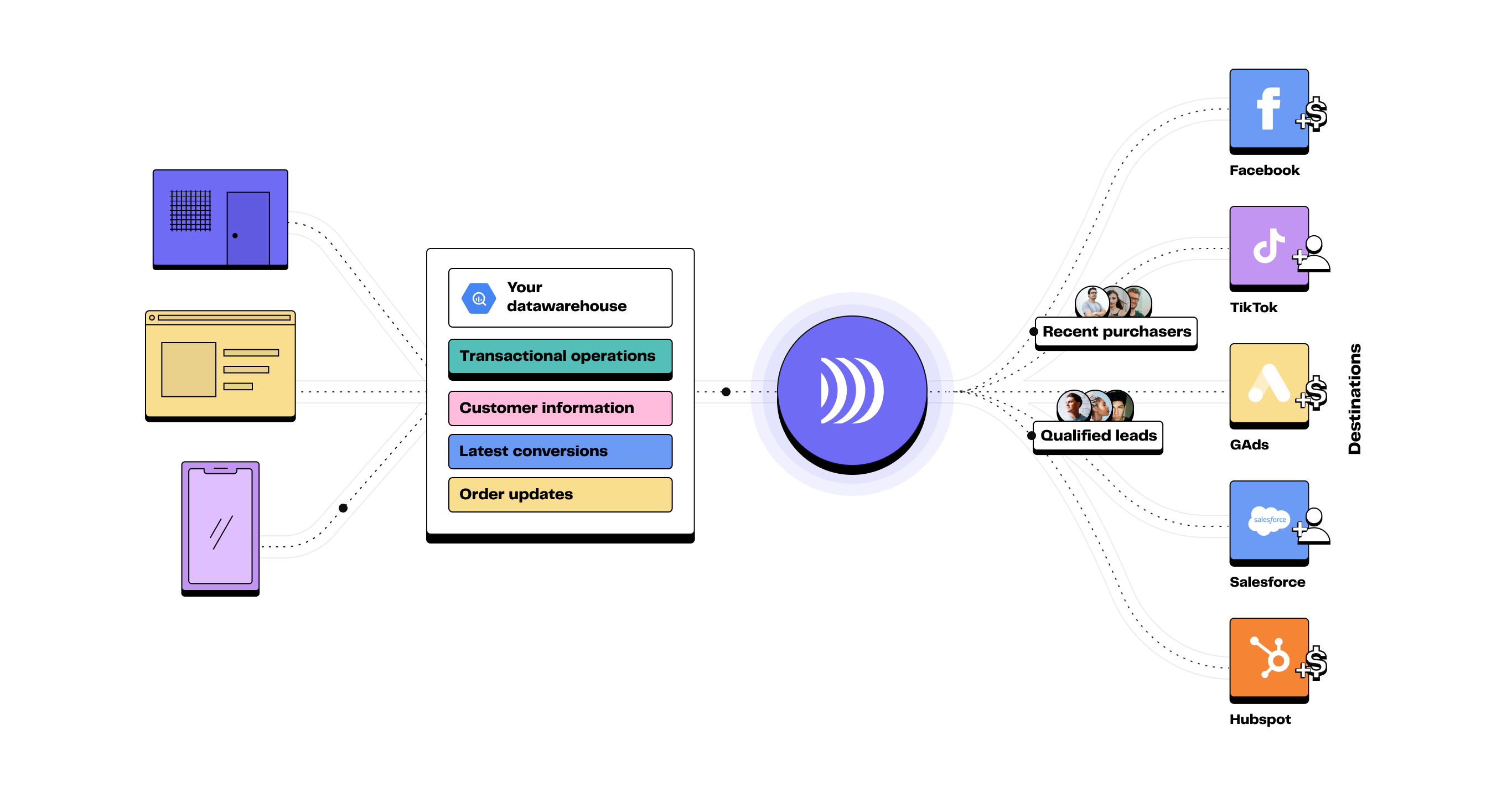
Proposer une expérience client personnalisée est désormais stratégique pour améliorer sa performance business. Avec un parcours d’achat plus fragmenté que jamais, il faut pour cela que les équipes marketing et commerciales disposent d’une vue client unifiée.
L'ETL permet de centraliser dans une source unique de vérité des données issues du CRM, des boutiques, des réseaux sociaux, du site web et du support client. En croisant ces informations, une entreprise peut mieux comprendre les parcours, détecter des opportunités et personnaliser ses actions.
C’est une étape indispensable pour construire une approche d’activation marketing fondée sur la donnée, et non plus sur l’intuition.


Les données qu'une Single Source of Truth devrait contenir
ETL, ELT, Reverse ETL : quelles différences ?
ETL vs ELT
Comme évoqué précédemment, l’ETL suit trois étapes bien définies : extraction des données, transformation dans un serveur intermédiaire, puis chargement vers l’entrepôt cible.
Avec l’ELT, l’ordre des étapes de transformation et de chargement change. Les données sont d’abord extraites, puis directement chargées dans l’entrepôt cible cloud (comme Redshift, BigQuery ou Snowflake).
Ce dernier dispose de capacités de transformation directement intégrées.
Cette approche très flexible permet de traiter des volumes importants de données, structurées ou non structurées. Elle profite de la puissance de calcul native des infrastructures cloud pour accélérer les traitements.
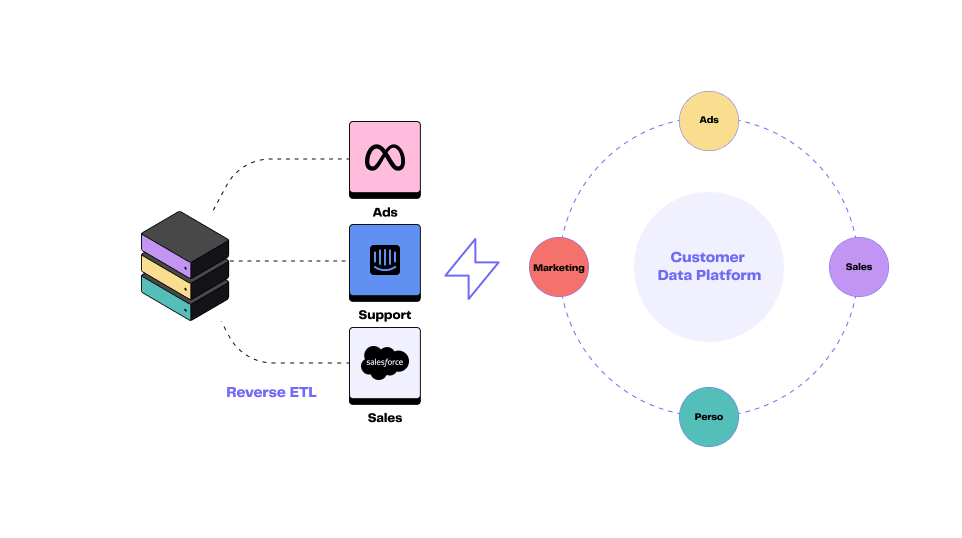
L'émergence du Reverse ETL
Comme son nom l’indique, le Reverse ETL suit une logique inversée par rapport à l‘ETL.
Il ne s'agit plus de centraliser vos données dans un entrepôt, mais de les envoyer vers vos applications métier : CRM, marketing automation, support client, plateformes publicitaires, etc.
On parle d’activation de la donnée. Concrètement, le Reverse ETL permet d’envoyer des segments clients, des scores de fidélité ou des comportements d’achat depuis le data warehouse.
Il est au service de vos équipes opérationnelles (sales, marketing, support, produit).
💡 Cette approche est au coeur de la vision de DinMo : faciliter l’exploitation des données client pour personnaliser l’expérience et piloter la performance.

Illustration du processus Reverse ETL
Les outils les plus populaires
Il existe une grande variété de solutions ETL, du logiciel open source à la solution clé en main en mode SaaS. Voici un aperçu des principales catégories.
Catégorie d’outils | Description | Principaux fournisseurs |
|---|---|---|
Outils traditionnels | Plateformes complètes, robustes, adaptées aux grandes infrastructures. Particularité : parfois lourdes à maintenir. | Talend, Informatica, SAP Data Services |
Outils cloud modernes | Solutions intégrées aux plateformes cloud. Flexibles, scalables, optimisées pour les architectures Big Data. | Azure Data Factory, AWS Glue, Google Cloud Dataflow |
Solutions légères (ETL as a Service) | Outils SaaS simples à déployer. Peu de maintenance, tarification à l’usage, adaptés aux équipes data agiles. | |
Applications open source | Solutions ouvertes et personnalisables. Permettent une forte flexibilité à moindre coût. Particularité : demandent parfois plus de ressources techniques. | Rudderstack, Apache NiFi, Singer, Airbyte (open source)* |
Les principales solutions d'ETL (*Outils considérés comme ELT-first)
Comment choisir ?
Le choix d’un outil ETL dépend avant tout des besoins métiers et techniques de l’entreprise. Plusieurs critères doivent être examinés :
Type de sources à connecter : bases relationnelles, API, fichiers plats, applications SaaS… Tous les outils ne couvrent pas le même périmètre.
Volume de données à traiter : certains outils sont mieux adaptés aux petits flux, d'autres aux environnements Big Data.
Fréquence des flux : en mode batch (traitements par lots réguliers) ou en temps réel (flux de données en continu).
Facilité d’usage, compatibilité cloud et coût : l’ergonomie de l’outil, son intégration avec les plateformes cloud et son modèle tarifaire sont autant de facteurs à prendre en compte pour garantir un bon retour sur investissement.
💡 Avant de choisir un outil, pensez à cartographier précisément les besoins opérationnels et techniques.
Challenges et cas d’usage de l’ETL
Le processus ETL est essentiel pour exploiter la donnée. Il s'accompagne également d’enjeux techniques et organisationnels. Voici comment en tirer un maximum de valeur.
Les principaux défis
Qualité et cohérence des données : la multiplication des sources augmente les risques de doublons, d’incohérences ou d’hétérogénéité des formats. Les étapes d’extraction et de transformation sont clés pour garantir la fiabilité de vos analyses.
Complexité croissante des architectures : augmentation des applications SaaS, diversité des systèmes de stockage, multiplicité des bases de données, etc. Les environnements techniques sont de plus en plus hétérogènes, ce qui rend l'intégration plus complexe.
Coût et maintenance : sans outil adapté, la maintenance des systèmes et pipelines ETL peut devenir lourde. L’enjeu est de trouver des solutions évolutives, capables de limiter les coûts techniques et humains.
Sécurité et conformité : le traitement des données sensibles impose de strictes exigences en matière de sécurité, d’auditabilité et de conformité aux réglementations comme le RGPD.
Cas d’usage concrets
Fiabiliser les reportings et la Business Intelligence
La phase de transformation de l’ETL vise à nettoyer, harmoniser et enrichir les données avant leur exploitation. C’est un prérequis pour garantir des indicateurs fiables et piloter l’activité de manière pertinente.
💡 Imaginons par exemple que vous soyez un acteur important du retail, présent en ligne et en magasin. Vous alimentez vos tableaux de bord avec les données issues de votre e-commerce, de vos points de vente et de votre CRM.
Grâce à un pipeline ETL, vous nettoyez les doublons, harmonisez les formats de dates et fusionnez les données client. Les dashboards Power BI affichent des prévisions de ventes plus fiables et permettent de mieux piloter vos stocks et vos campagnes de fidélisation.
Unifier les données issues de sources multiples…
Collecter et agréger les données provenant du CRM, des ventes, du support client ou des outils analytics est indispensable pour casser les silos d'information.
Une base unifiée permet de mieux comprendre les parcours clients et d’aligner les équipes marketing, sales et produit autour d’une vue client 360°.
… et les préparer pour l’activation
L’ETL joue aussi un rôle clé dans la préparation des données pour des campagnes plus précises et efficaces.
Segmentation avancée, scoring comportemental, enrichissement des profils… Toutes ces étapes reposent sur des données fiables et centralisées dans une source de vérité.
💡 Grâce au Reverse ETL, les données transformées peuvent alors être synchronisées automatiquement vers les outils métier, pour personnaliser l’expérience client à grande échelle.
Conclusion
Face à la diversité croissante des sources de données, un processus ETL bien conçu permet de collecter, organiser, fiabiliser et exploiter efficacement l'information.
Il constitue la première étape pour passer de données brutes et éparpillées à une activation marketing performante.
💡 Envie de découvrir comment une approche moderne de la donnée client peut optimiser votre performance marketing ? Découvrez les solutions DinMo.
FAQ
Quelle est la différence entre un pipeline de données et un processus ETL ?
Quelle est la différence entre un pipeline de données et un processus ETL ?
Un pipeline de données désigne un flux automatisé permettant de déplacer ou de transformer des données d’un point A à un point B.
Le processus ETL (Extract, Transform, Load) désigne une méthode d’intégration des données structurée en trois étapes : extraction, transformation, chargement. Il s’implémente généralement à travers un ou plusieurs pipelines automatisés.
Certains pipelines sont construits à l’aide d’outils no-code ou cloud, d’autres sont développés sur mesure par des équipes techniques. Dans tous les cas, l’objectif reste le même : rendre la donnée fiable, disponible et exploitable dans les outils métier.
👉 Pour en savoir plus, découvrez notre article sur les différences entre les Reverse ETL et les iPaaS
Quels métiers sont concernés par un projet ETL ?
Quels métiers sont concernés par un projet ETL ?
Un projet ETL mobilise plusieurs types de profils.
Les équipes data (data engineers, architectes…) conçoivent et supervisent les flux. Les utilisateurs finaux sont souvent les équipes métier : BI, marketing, ventes, produit, finance…
Elles s’appuient sur des données fiables et centralisées pour piloter leur activité.
Un bon processus ETL permet de faire le lien entre les enjeux techniques et les besoins opérationnels, en garantissant la qualité de l’information.
Comment garantir la sécurité et la conformité des données dans un processus ETL ?
Comment garantir la sécurité et la conformité des données dans un processus ETL ?
La sécurité des données dans un processus ETL repose sur plusieurs piliers : chiffrement, contrôle des accès, audit des traitements et traçabilité. Il est essentiel de limiter les permissions, de protéger les données sensibles et de documenter chaque étape.
La conformité réglementaire (comme le RGPD ou le CCPA) impose aussi de savoir où circulent les données, combien de temps elles sont conservées, et à quelles fins elles sont utilisées. Un ETL bien gouverné contribue à une stratégie de gestion des données responsable et durable.