Le rôle central du data warehouse dans une Modern Data Stack
8min • Édité le 5 févr. 2026


Olivier Renard
Content & SEO Manager
Le marché des entrepôts de données (data warehouses) cloud pesait déjà 6,1 milliards de dollars en 2023. D’ici 2032, il devrait dépasser les 37 Mds $, porté par une croissance annuelle moyenne de 22,5 % selon Global Market Insights.
Une confirmation de l’intérêt grandissant des entreprises pour des architectures data modernes et évolutives. Le data warehouse n’est plus un outil réservé à la BI (Business Intelligence) : il tient un rôle clé pour centraliser et exploiter les données à grande échelle.
Les informations à retenir :
Un data warehouse est une plateforme qui centralise, organise et rend exploitables les données d’une entreprise ou d’une organisation.
Il se distingue d’une base de données ou d’un data lake par sa structure, pensée pour l’analyse et la prise de décision. Il existe de nombreux fournisseurs sur le marché.
Cet entrepôt joue le rôle de référentiel central en intégrant des données issues de sources variées, et en conservant leur historique.
Il constitue le socle d’une Modern Data Stack. Une CDP composable s’appuie sur les données présentes dans le data warehouse pour faciliter leur activation par les équipes métier : marketing, produit, finance, vente.
🔍 Découvrez ce qu’est un data warehouse et ce qui le distingue des autres solutions de stockage. Apprenez à le mettre en place et à l'intégrer à votre architecture pour tirer pleinement parti de vos données. 🚀
Qu’est-ce qu’un data warehouse
Un data warehouse (ou entrepôt de données en français) est une plateforme conçue pour intégrer, stocker et organiser des volumes importants de données issues de sources variées.
Il a pour objectif de faciliter l’analyse et la prise de décision à l’échelle de l’organisation. En ce sens, il se distingue d’une base de données classique, destinée à exécuter des opérations courantes.
Le data warehouse ne se limite pas à la simple collecte et au stockage d’informations. Il organise la donnée, l’historise et la rend exploitable pour différents usages : tableaux de bord, indicateurs, segmentation, modélisation, etc. Il agit comme un référentiel fiable, prêt à alimenter les outils métier sans intervention manuelle.
Historiquement, les premiers entrepôts de données (EDD) sont apparus dans les années 1980, à l’initiative de pionniers comme Bill Inmon ou Ralph Kimball. Ils étaient conçus pour fonctionner sur des infrastructures locales (on-premise), souvent complexes à maintenir.
Aujourd’hui, les data warehouses cloud, comme BigQuery, Snowflake ou Redshift, offrent plus de flexibilité et de simplicité d'utilisation. Ils s’intègrent pleinement aux outils opérationnels via des connecteurs, APIs ou pipelines automatisés.
Principaux usages
Le rôle du data warehouse a largement évolué. À l’origine, il servait principalement à la business intelligence et au reporting, en agrégeant les données issues des différents services de l’entreprise.
Il permettait de suivre des KPIs, de produire des rapports consolidés et d’en harmoniser la lecture.
Désormais, son utilisation dépasse largement le périmètre de la BI. Un entrepôt de données moderne peut être utilisé pour :
Créer des segments clients en fonction de leur comportement ou leur historique,
Alimenter des modèles de scoring ou de recommandation,
Enrichir une vision customer 360°,
Suivre la performance produit dans le temps,
Ou encore mieux comprendre le parcours client.
Les équipes marketing s’appuient de plus en plus sur ces données pour piloter leurs actions, personnaliser les expériences et identifier de nouveaux leviers de croissance. Plus généralement, le data warehouse est là pour répondre aux besoins de toutes les équipes : produit, finance ou support.
Quelle différence entre data warehouse, base de données et data lake
Pour construire une architecture de gestion de données, il est important de comprendre les distinctions entre un data warehouse, une base de données relationnelle ou un data lake. Chacun a ses spécificités, ses cas d’usage et ses limites.
Critère | Data warehouse | Base de données (Database) | Data lake |
|---|---|---|---|
Objectif | Centralisation des données, analyse, reporting, aide à la décision (OLAP*). | Exécution d’opérations courantes (transactions, enregistrements - OLTP*) | Stockage massif et brut de données diverses |
Type de données | Données historiques, nettoyées, prêtes à l’analyse | Données opérationnelles, temps réel | Données brutes, structurées ou non (fichiers, logs, vidéos…) |
Coût | Modéré à élevé selon l’usage et la volumétrie | Moindre coût à l’échelle, mais pas conçu pour l’analyse | Peu coûteux à stocker, mais plus cher à exploiter |
Cas d’usage | Tableaux de bord, segmentation, analyse multi-source, activation des données | CRM, gestion de commandes, applications métiers | IA, machine learning, stockage long terme |
Principaux fournisseurs | Snowflake, BigQuery, Redshift, Azure Synapse | MySQL, PostgreSQL, SQL Server | Amazon S3, Azure Data Lake, Google Cloud Storage |
Data warehouse vs Database vs Data lake
Deux autres concepts reviennent souvent lorsqu’on parle de gestion des données : le data mart et le lakehouse.
Un data mart est un petit entrepôt de données dédié à un service ou un usage précis (marketing, finance, RH…). Il s’appuie généralement sur un data warehouse principal et permet d’accéder rapidement à des données ciblées.
Le lakehouse est un terme popularisé par des acteurs comme Databricks. Il désigne une architecture hybride entre un data lake et un data warehouse. Son objectif est de combiner le meilleur des deux mondes : la flexibilité du data lake et l’organisation du data warehouse.
Comment cela fonctionne dans la pratique
Un data warehouse repose sur une architecture simple et puissante, pensée pour rendre les données exploitables et fiables. Son fonctionnement s’appuie sur quatre grandes étapes :
Ingestion : les données sont collectées depuis plusieurs sources (CRM, site web, application mobile, ERP…). Elles sont intégrées via des flux ETL (Extract, Transform, Load) ou ELT selon le besoin.
Stockage : les données sont conservées dans un environnement stable, avec une structure claire, souvent basée sur des schémas en étoile ou en flocon.
Modélisation : elles sont ensuite organisées autour de faits (ex : 'achat') et de dimensions (ex : 'client', 'produit', 'date') pour faciliter leur lecture et leur croisement.
Restitution : les données peuvent ensuite être consultées, analysées ou activées dans d'autres applications.
Schémas en étoile et en flocon
Dans un entrepôt de données, les informations sont souvent organisées selon deux modèles :
Le modèle en étoile : simple, rapide à interroger, facile à maintenir. Toutes les dimensions (ex. 'client', 'produit', 'date') sont directement reliées à la table de faits, comme les branches d’une étoile.
Le modèle en flocon : plus détaillé, plus normalisé, mais parfois plus complexe. Les dimensions sont découpées en sous-tables pour éviter les redondances. Par exemple, la dimension 'produit' peut être subdivisée en plusieurs tables qui lui sont reliées : 'taille', 'catégorie', etc.
💡 Le nom de l’outil Snowflake est d’ailleurs un clin d’œil à cette structuration “en flocon”, bien qu’il ne s’y limite pas.

Schéma en étoile vs schéma en flocon
Gouvernance et interopérabilité : le rôle du data layer
Le data layer représente la couche centrale du data warehouse. Elle sert d’intermédiaire entre les sources brutes (CRM, site web, boutique) et les usages métier.
Son rôle est de stocker, préparer et standardiser les informations afin d’en garantir la qualité, la cohérence et la compatibilité avec les autres outils de la stack (BI, CRM, CDP composable…).
Le data layer intègre des règles de gouvernance et de sécurité permettant, par exemple, de restreindre l’accès à certaines données selon les équipes ou les rôles.
Un data warehouse moderne garantit à la fois la gouvernance (qualité, conformité, droits d’accès) et l’interopérabilité avec les outils tiers. Il permet à chaque équipe de s’appuyer sur une donnée fiable, documentée et disponible dans son environnement de travail habituel.
Comment concevoir un data warehouse pour votre entreprise
Construire un data warehouse efficace ne se résume pas à choisir un fournisseur ou une technologie. C’est un projet structurant qui doit avant tout répondre à des besoins concrets.
Découvrez les principales étapes pour mettre en place une solution adaptée à votre organisation.
1️⃣ Identifier les besoins métier
Il faut avant toute chose comprendre ce que les équipes attendent de la donnée :
Quelles décisions doivent être facilitées ?
Quels indicateurs sont critiques ?
Quelles sources d’information sont sous-utilisées ?
Cela commence toujours par un dialogue avec les équipes concernées : marketing, produit, finance, support.
2️⃣ Sélectionner les sources de données
Une fois les besoins clarifiés, il faut cartographier les sources de données à intégrer. Il peut s’agir de votre CRM, de votre site web, de vos points de vente, de vos outils analytics ou encore de votre logistique.
L’objectif est de centraliser les données pertinentes, qu’elles soient structurées ou semi-structurées, tout en assurant leur qualité.
3️⃣ Choisir l’architecture technique
Faut-il héberger votre entrepôt de données en local (on-premise) ou opter pour une solution cloud comme Snowflake, BigQuery, Redshift, Databricks ou Synapse ?
Les CDW (Cloud Data Warehouses) offrent plus de flexibilité, une meilleure évolutivité et une interopérabilité renforcée avec les autres briques de la stack. Ils conviennent à la majorité des entreprises et permettent aux équipes data de se concentrer sur des tâches à plus forte valeur ajoutée.
4️⃣ Concevoir une modélisation adaptée
La modélisation consiste à définir la façon dont les données seront organisées et reliées entre elles. Un modèle clair facilite les requêtes et l’analyse en structurant les données autour de faits et de dimensions.
Il permet aussi d’alimenter les tableaux de bord, les scores marketing ou les reporting financiers sans ressaisie ni retraitement manuel.
5️⃣ Intégrer le data warehouse à votre environnement existant
Le data warehouse doit s’articuler avec les outils en place : CRM, plateformes marketing, logiciels financiers, solutions de BI, etc. C’est cette interopérabilité qui permet l’exploitation de la donnée par les équipes.
La CDP composable DinMo se connecte directement à votre data warehouse pour activer les données clients sans duplication.

Fonctionnement de la CDP composable DinMo
Les erreurs à éviter
Concevoir sans objectif clair : sans alignement avec les enjeux métiers, le projet risque de devenir une usine à gaz.
Négliger l’activation : stocker des données ne suffit pas. Il faut penser dès le départ à comment elles seront utilisées (ex : segmentation, campagnes, automatisation).
Isoler la solution des utilisateurs finaux : un data warehouse n’a de valeur que s’il alimente les outils utilisés au quotidien par les équipes opérationnelles.
Le rôle du data warehouse dans une architecture moderne
Le data warehouse cloud occupe une place centrale dans la modern data stack. Il agit comme un socle de référence, sur lequel reposent les autres briques de l’écosystème data de l’entreprise.
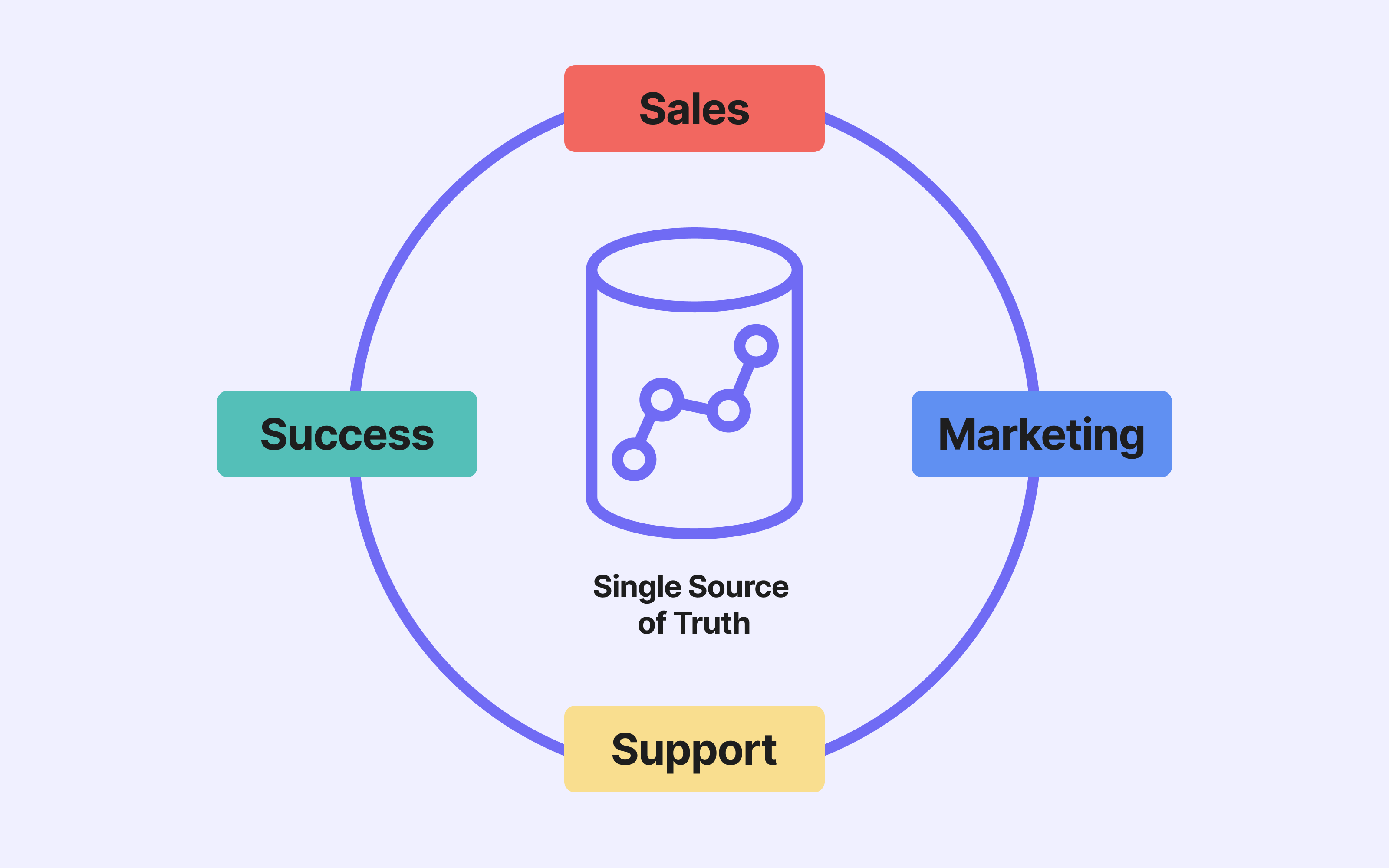
Une source unique de vérité
En centralisant des données issues de multiples sources, le data warehouse permet de construire une vue unifiée et à jour.
Il devient la source de vérité (ou single source of truth), garantissant que toutes les équipes travaillent avec les mêmes chiffres, les mêmes définitions, et les mêmes règles métiers.
Une brique interconnectée à toute la stack
Le data warehouse est alimenté par des pipelines ETL ou ELT, qui extraient, transforment et chargent les données. Il peut être connecté à des outils d’observabilité, qui surveillent la qualité, la fraîcheur ou la disponibilité des données.
Enfin, il peut transmettre directement les données à des outils métier ou analytiques via des connecteurs ou des plateformes comme DinMo, sans duplication.
La forte complémentarité entre data warehouse et CDP composable
Comme nous l’avons vu précédemment, le data warehouse stocke et organise l’information pour la rendre exploitable par les équipes métier. Elle doit pour cela être disponible dans leurs environnements quotidiens : CRM, plateformes publicitaires, etc
Une Customer Data Platform (CDP) composable sert de pont pour activer la donnée présente dans le data warehouse. Sa conception modulaire la distingue des CDP traditionnelles (ou packagées).
CDP packagée vs CDP composable
Une CDP packagée regroupe toutes les fonctions (collecte, stockage, unification, activation) dans un seul outil. En stockant la donnée dans sa propre base, elle crée donc une deuxième source de vérité en plus de celle déjà en place dans l’entreprise.
Cela induit un coût initial plus élevé, une sécurité moindre et une faible personnalisation.
À l’inverse, une CDP composable s’appuie directement sur le data warehouse existant. Elle n’en copie pas les données, mais les active à la source.
De cette façon, DinMo permet aux équipes marketing, vente ou produit d’agir sur leurs données sans dépendre des équipes techniques.


Catégories de CDP
Cas d’usage concrets
Cette approche offre de nombreux avantages. Elle permet de :
Segmenter les clients en fonction de critères comportementaux ou transactionnels,
Enrichir les données CRM avec des informations issues du produit ou du support,
Calculer et utiliser la Lifetime Value (LTV) dans des campagnes marketing ciblées,
Personnaliser les expériences clients à grande échelle.
Le data warehouse reste la base. La CDP composable le complète efficacement pour rendre les données directement utiles et activables, sans connaissance technique.
Conclusion
Le data warehouse cloud s’impose aujourd’hui comme un socle stratégique de toute architecture data moderne. Il permet de centraliser, structurer et fiabiliser les données pour mieux les exploiter, les analyser et les activer.
Longtemps réservé aux équipes techniques, il devient un outil au service de tous les métiers : marketing, produit, commerce, finance ou direction. Intégré à l’écosystème existant, il permet de construire une donnée de qualité, accessible et réellement actionnable.
👉 Pour aller plus loin dans l’activation de vos données, découvrez comment la CDP composable DinMo aide à tirer parti de votre data warehouse, sans duplication et sans dépendance technique.
*OLAP = Online Analytical Processing et OLTP = Online Transaction Processing