Understanding the ETL process: The complete guide
8min • Last updated on Aug 3, 2025


Olivier Renard
Content & SEO Manager
On average, a company uses 112 SaaS applications (BetterCloud). A figure that exceeds 150 for organisations with more than 5,000 employees, a 40% increase since 2020.
Faced with this explosion of tools, data is scattered across numerous sources: CRM, ERP, e-commerce platforms, analytics, customer support, and more. Centralising, cleaning, and leveraging this data has become a real challenge for businesses.
This is precisely the role of the ETL process: turning raw data streams into a powerful lever for analysis and performance.
Key Takeaways:
ETL stands for Extract, Transform, Load. It’s a process that extracts, transforms and loads data to make it usable.
It is essential to consolidate dispersed data in order to improve analytics, business intelligence or customer relations.
ETL differs from other integration models, such as ELT. Reverse ETL, meanwhile, describes the opposite movement: sending data from the data warehouse back into business tools.
Choosing the right ETL tool simplifies data management and optimises your data and marketing operations.
👉 Discover how the ETL process works and why it remains a cornerstone of any modern data strategy. Learn about the main tools and use cases 🔍
What is the ETL process?
ETL refers to the Extract, Transform, Load technology.
This process is designed to collect data from multiple sources, transform it, and then import it into a target system so it can be used effectively.
It plays a crucial role in data management and analytics. Without ETL, data often remains raw, scattered and difficult to exploit.
By gathering and organising information, ETL facilitates reporting, business intelligence, and the building of a unified customer view.
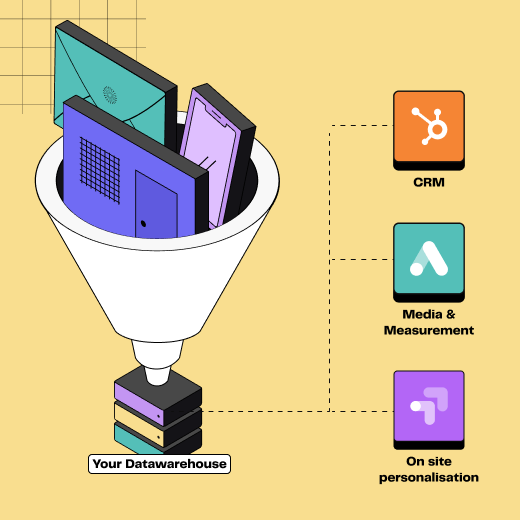
A three-step process
1️⃣ Extraction
The first step involves retrieving data from different sources. These may be relational databases (MySQL, Oracle), CRM systems, e-commerce platforms, APIs, or even simple CSV files.
2️⃣ Transformation
Extracted data is often inconsistent, containing different formats, duplicates or missing values.
The transformation phase involves cleaning, enriching, reformatting and aggregating the data so it is coherent and ready for business use.
3️⃣ Loading
The final step is to load the transformed data into a data warehouse, data lake, or any other target system. The data can then be used for analysis, marketing personalisation or reporting.
Initial loads are comprehensive, followed by periodic (or incremental) updates.
💡 In some modern architectures, the extraction, transformation and loading stages do not occur sequentially. They can run in parallel to save time.


Extract Transform Load process illustration
Importance in data management
Explosion of data sources
Originally, data was stored locally on internal company servers: invoices, commercial info, stock, HR data. Early data architectures were based on a few internal relational databases.
Today, data flows in from everywhere: SQL and NoSQL databases, SaaS tools, connected objects (IoT), activity logs, CRMs, social media...
This multiplication of sources has created challenges: different formats, varied protocols, inconsistent quality, and the risk of duplication or errors.
Without a clear methodology to organise this growing volume of data, its exploitation becomes complex, costly and unreliable.
Organising data for analysis
To generate value, data must first be centralised, cleaned, and prepared. This is the core mission of ETL: consolidating disparate information to make it usable.
This process is essential for feeding Business Intelligence tools, performing reliable analysis, or launching data science projects. It forms the foundation of a data-driven strategy by ensuring access to accurate and up-to-date insights.
A lever for performance
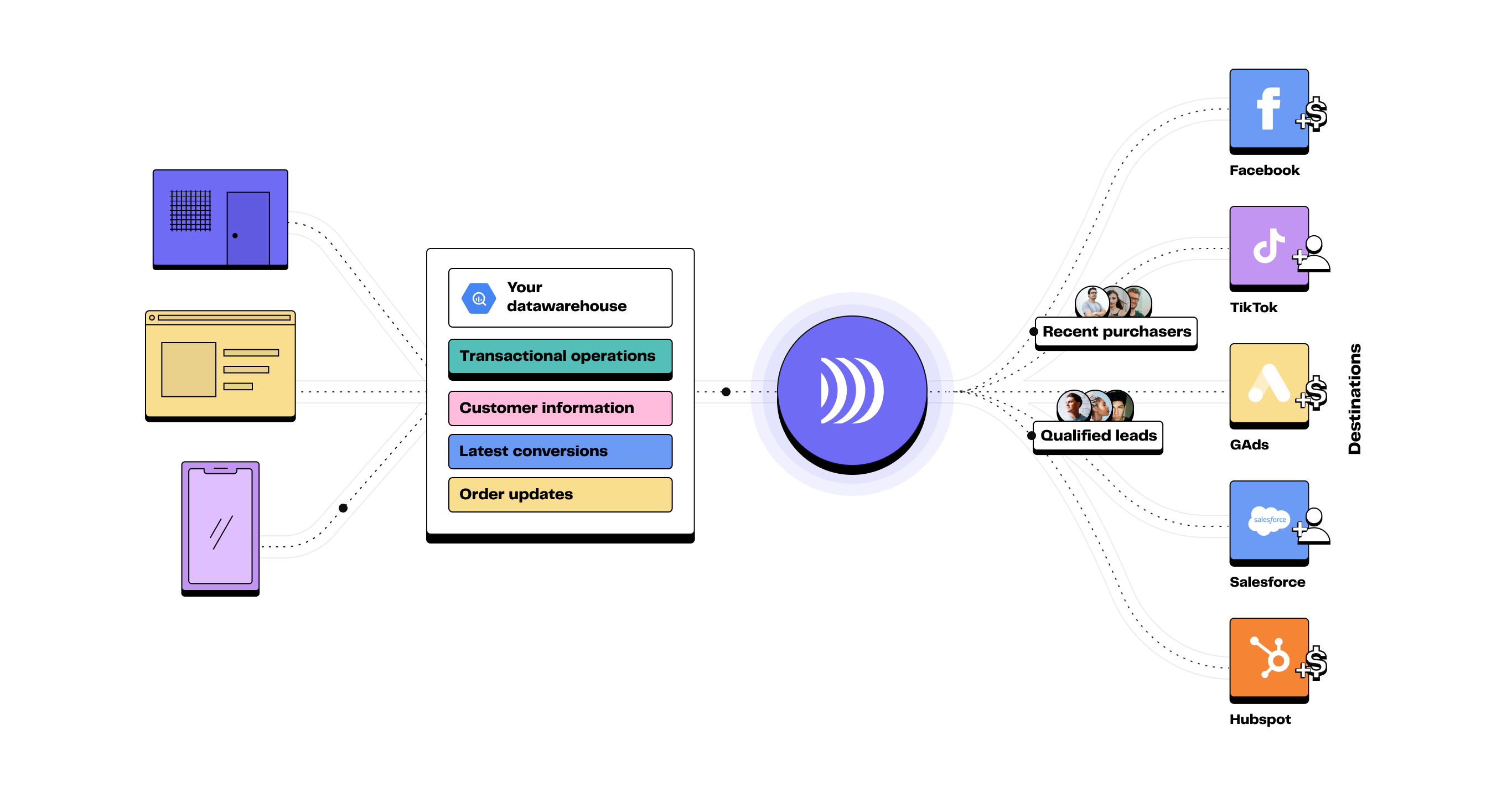
Delivering a personalised customer experience is now a business performance driver. With purchase journeys more fragmented than ever, marketing and sales teams need a single customer view.
ETL consolidates data from your CRM, shops, social media, website and customer support into one place. By cross-referencing this information, businesses can better understand journeys, detect opportunities, and tailor their actions.
It’s a crucial step to building a marketing activation strategy based on data rather than intuition.


All the information we recommend centralising in a Single Source of truth
ETL, ELT, Reverse ETL: what’s the difference?
ETL vs ELT
As mentioned earlier, the ETL process follows three clearly defined steps: data extraction, transformation on an intermediate server, and then loading into the target warehouse.
With ELT, the order of transformation and loading steps is reversed. Data is first extracted, then directly loaded into the target cloud warehouse (such as Redshift, BigQuery or Snowflake).
These platforms have built-in transformation capabilities.
This highly flexible approach allows for the processing of large volumes of both structured and unstructured data. It takes advantage of the native computing power of cloud infrastructures to accelerate processing.
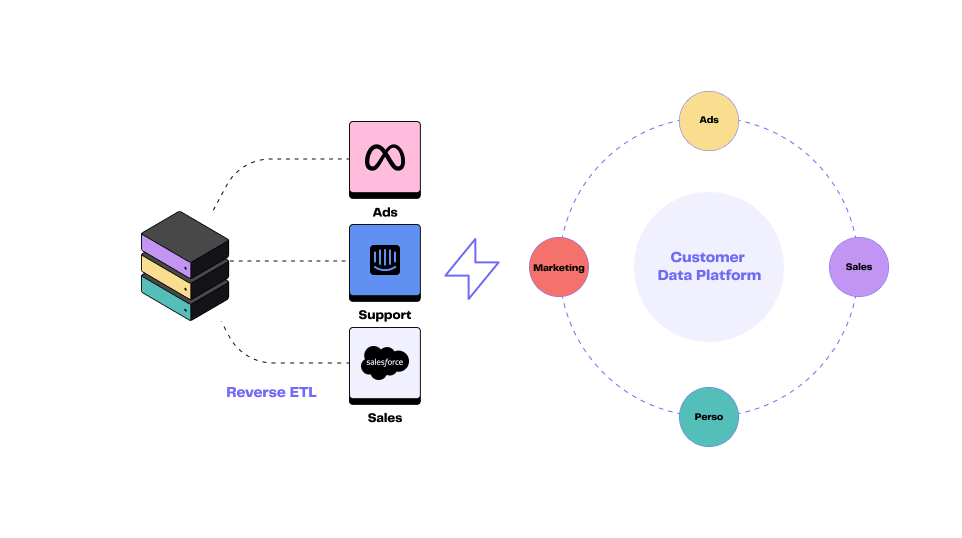
The rise of Reverse ETL
As the name suggests, Reverse ETL operates in the opposite direction to ETL.
Rather than centralising your data in a warehouse, it focuses on delivering that data to your business applications: CRM, marketing automation tools, customer support platforms, advertising channels, and more.
This is known as data activation. In practical terms, Reverse ETL allows you to push customer segments, loyalty scores, or purchasing behaviours directly from your data warehouse.
It serves operational teams such as sales, marketing, support, and product.
💡 This approach is central to DinMo’s mission: making it easier to leverage customer data in order to personalise the experience and drive performance.

Illustration of Reverse ETL process
Most popular tools
There is a wide variety of ETL solutions, from open source software to turnkey SaaS solutions. Here is a breakdown of the most common categories.
Tool category | Description | Main providers |
|---|---|---|
Traditional tools | Comprehensive platforms for large infrastructures. Powerful but sometimes heavy to maintain. | Talend, Informatica, SAP Data Services |
Modern cloud tools | Integrated with cloud platforms. Flexible, scalable and Big Data ready. | Azure Data Factory, AWS Glue, Google Cloud Dataflow |
Lightweight solutions (ETL as a Service) | SaaS tools that are easy to deploy. Low maintenance and usage-based pricing. Ideal for agile teams. | |
Open source applications | Open, customisable solutions. Provide high flexibility at low cost. However, they sometimes require more technical skills. | Rudderstack, Apache NiFi, Singer, Airbyte (open source)* |
Main ETL solutions (*Tools considered ELT-first)
How to choose?
Choosing an ETL tool depends primarily on your business and technical needs. Several criteria should be considered:
Types of data sources to connect: relational databases, APIs, flat files, SaaS applications… Not all tools cover the same range.
Data volumes to process: some tools are better suited to small data flows, while others are designed for Big Data environments.
Data flow frequency: batch processing (regular data loads) vs. real-time (continuous data streams).
Ease of use, cloud compatibility and cost: the tool’s interface, its integration with cloud platforms, and its pricing model are all key factors in ensuring a solid return on investment.
💡 Before selecting a tool, start by clearly mapping your operational and technical requirements.
ETL challenges and use cases
The ETL process is essential for unlocking the value of your data, but it also comes with technical and organisational challenges. Here’s how to get the most out of it.
Key challenges
Data quality and consistency: multiple data sources increase the risk of duplicates, inconsistencies, or format mismatches. The extraction and transformation phases are critical for ensuring trustworthy analytics.
Increasing architectural complexity: the rise in SaaS applications, variety of storage systems and databases creates increasingly heterogeneous technical environments, complicating integration.
Cost and maintenance: without the right tools, managing ETL systems and pipelines can be burdensome. The goal is to choose scalable solutions that minimise technical and human costs.
Security and compliance: processing sensitive data requires strict security, auditability, and regulatory compliance (e.g. GDPR).
Frequent use cases
Ensuring reliable reporting and business intelligence
The transformation stage of ETL is where data is cleaned, harmonised, and enriched prior to use. This is essential for generating reliable KPIs and effective business management.
💡 Imagine you’re a major retail player, with both online and in-store activity. Your dashboards rely on data from your e-commerce platform, physical shops, and CRM system.
An ETL pipeline helps remove duplicates, unify date formats, and merge customer data. Power BI dashboards now deliver more accurate sales forecasts and help optimise stock management and loyalty campaigns.
Unifying data from multiple sources...
Bringing together data from your CRM, sales, customer support or analytics tools is crucial to breaking down data silos.
A unified base enables a clearer understanding of customer journeys and aligns marketing, sales and product teams around a single 360° customer view.
...and preparing it for activation
ETL also plays a crucial role in preparing data for more targeted, effective campaigns.
Advanced segmentation, behavioural scoring, profile enrichment. All these steps rely on centralised, trustworthy data stored in a single source of truth.
💡 With Reverse ETL, your transformed data can then be automatically synced to business tools, enabling personalisation at scale.
Conclusion
As data sources become increasingly diverse, a well-designed ETL process enables you to collect, organise, clean and leverage insights effectively.
It is the first step in turning raw, fragmented data into high-performing marketing activation.
💡 Keen to explore how a modern approach to customer data can boost your marketing performance? Discover DinMo’s solutions.
FAQ
What is the difference between a data pipeline and an ETL process?
What is the difference between a data pipeline and an ETL process?
A data pipeline refers to an automated flow used to move or transform data from point A to point B.
The ETL process (Extract, Transform, Load) is a structured data integration method with three stages: extraction, transformation, and loading. It is typically implemented through one or more automated pipelines.
Some pipelines are built using no-code or cloud-based tools, while others are custom-developed by technical teams. In all cases, the goal remains the same: to make data reliable, accessible, and usable across business tools.
👉 To learn more, read our article on the differences between Reverse ETL and iPaaS.
Which roles are involved in an ETL project?
Which roles are involved in an ETL project?
An ETL project involves various profiles.
Data teams (data engineers, architects, etc.) design and oversee the flows. The end users are often business teams: BI, marketing, sales, product, and finance.
They rely on centralised, trustworthy data to guide their operations.
A well-structured ETL process bridges the gap between technical needs and business requirements by ensuring data quality and consistency.
How can you ensure data security and compliance in an ETL process?
How can you ensure data security and compliance in an ETL process?
Data security in an ETL process relies on several key principles: encryption, access control, processing audits, and traceability. It is essential to restrict permissions, protect sensitive data, and document every step.
Regulatory compliance (such as GDPR or CCPA) also requires knowing where data is flowing, how long it is retained, and for what purpose it is used.
A well-governed ETL contributes to a responsible and sustainable data management strategy.